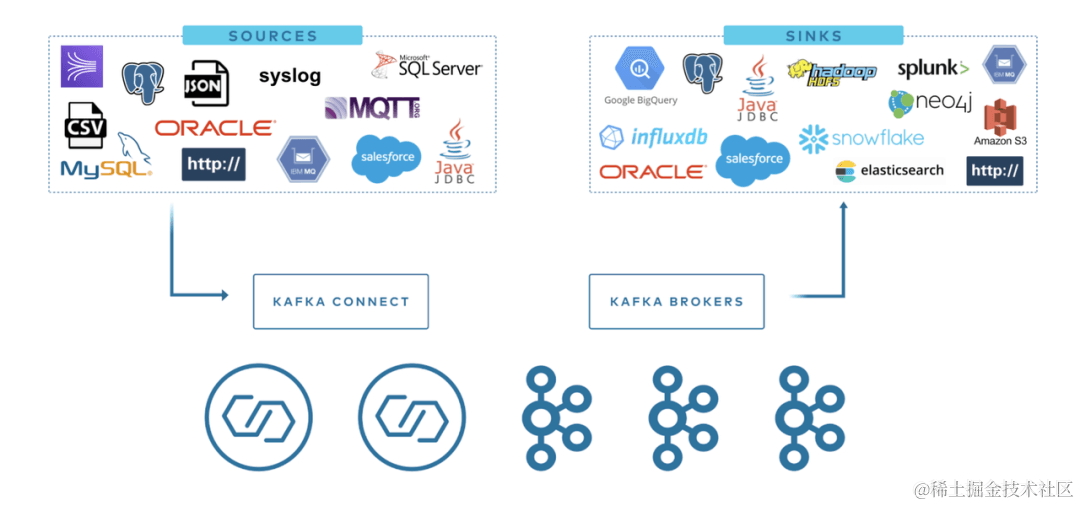
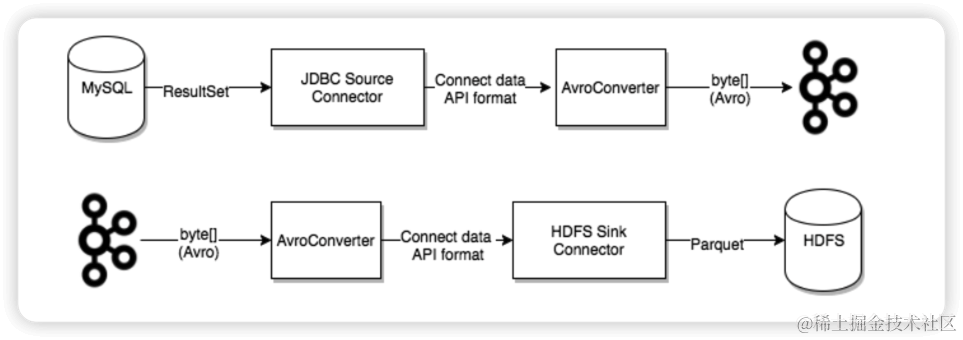
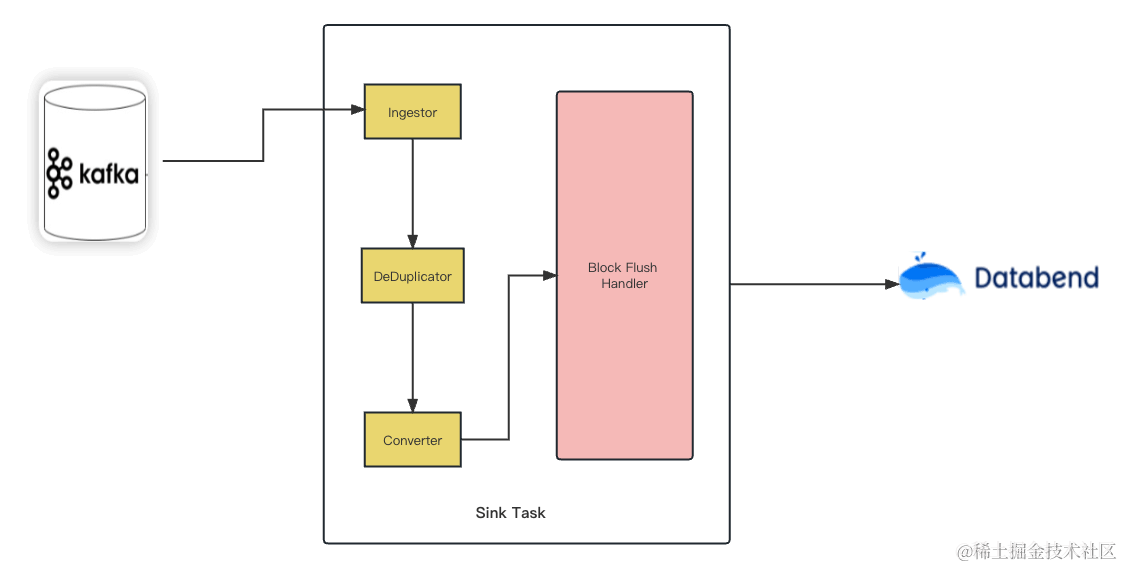
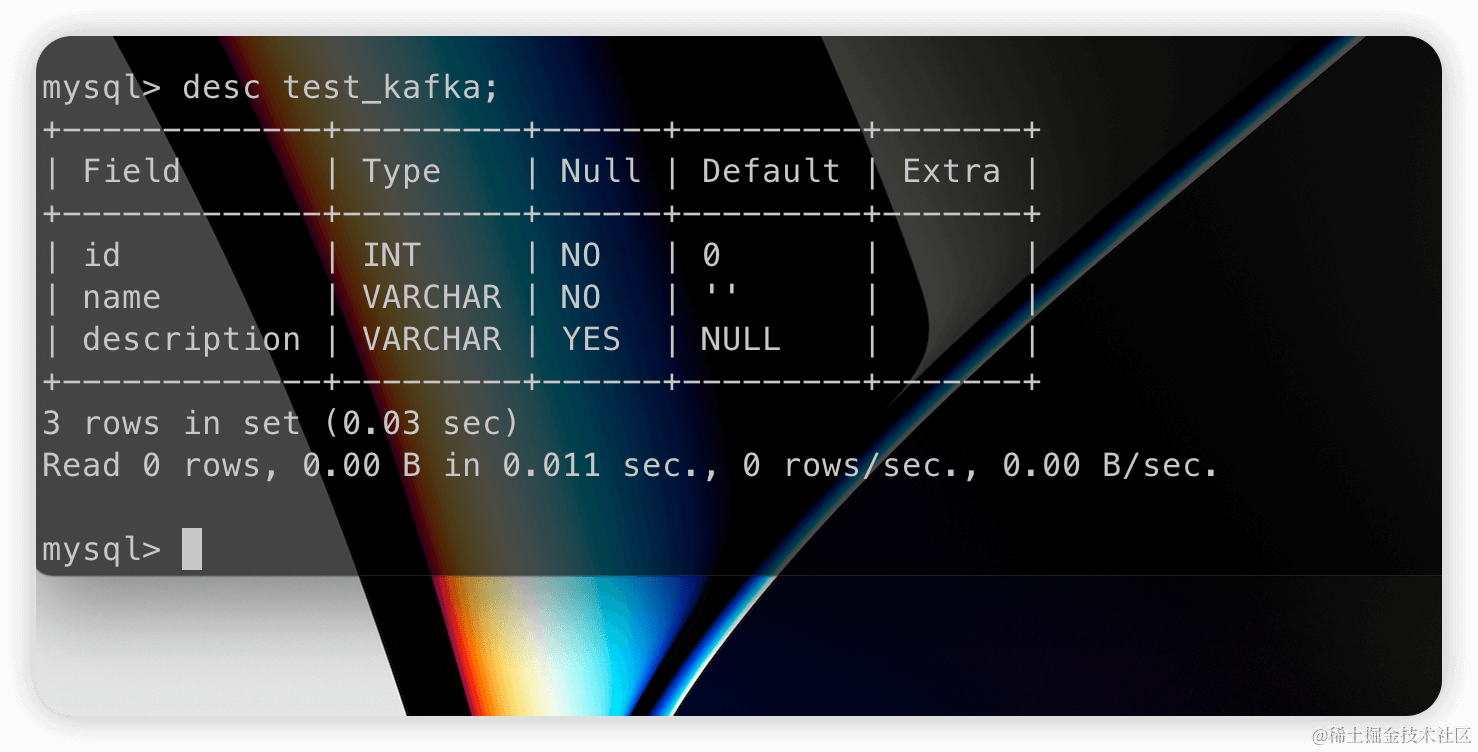
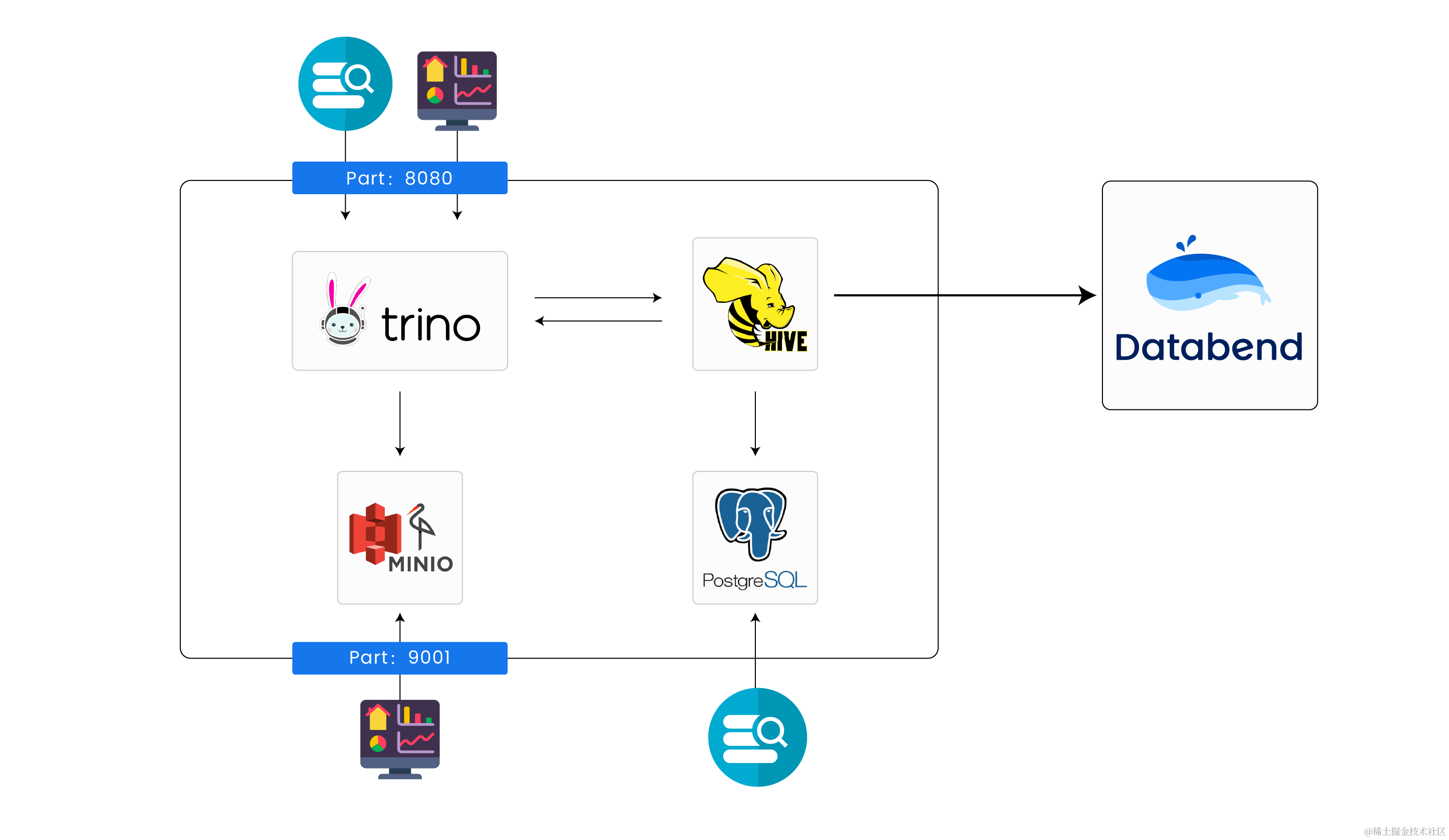
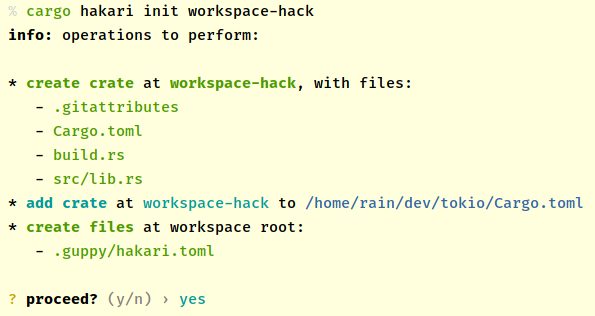
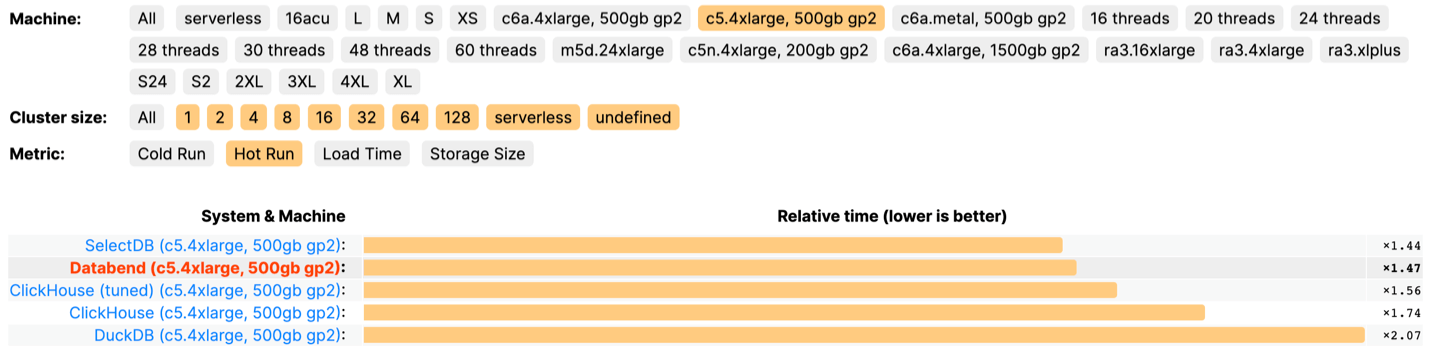
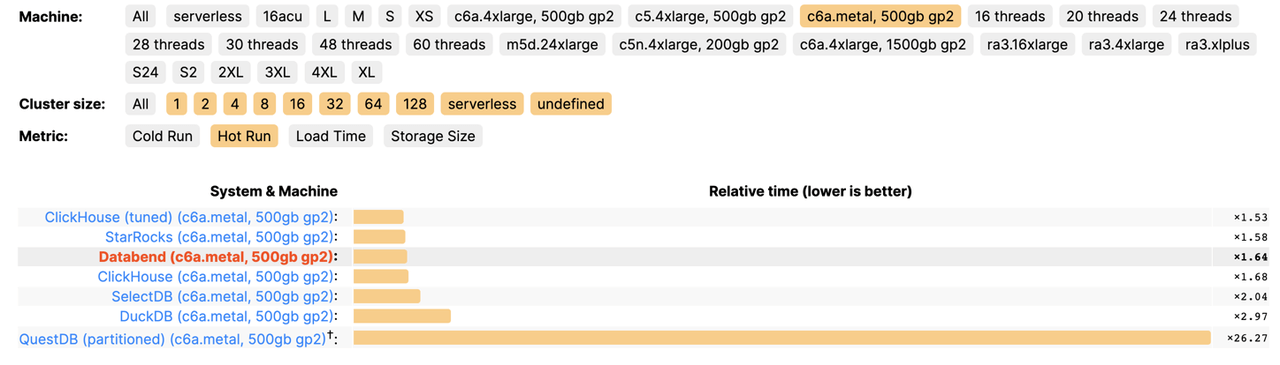
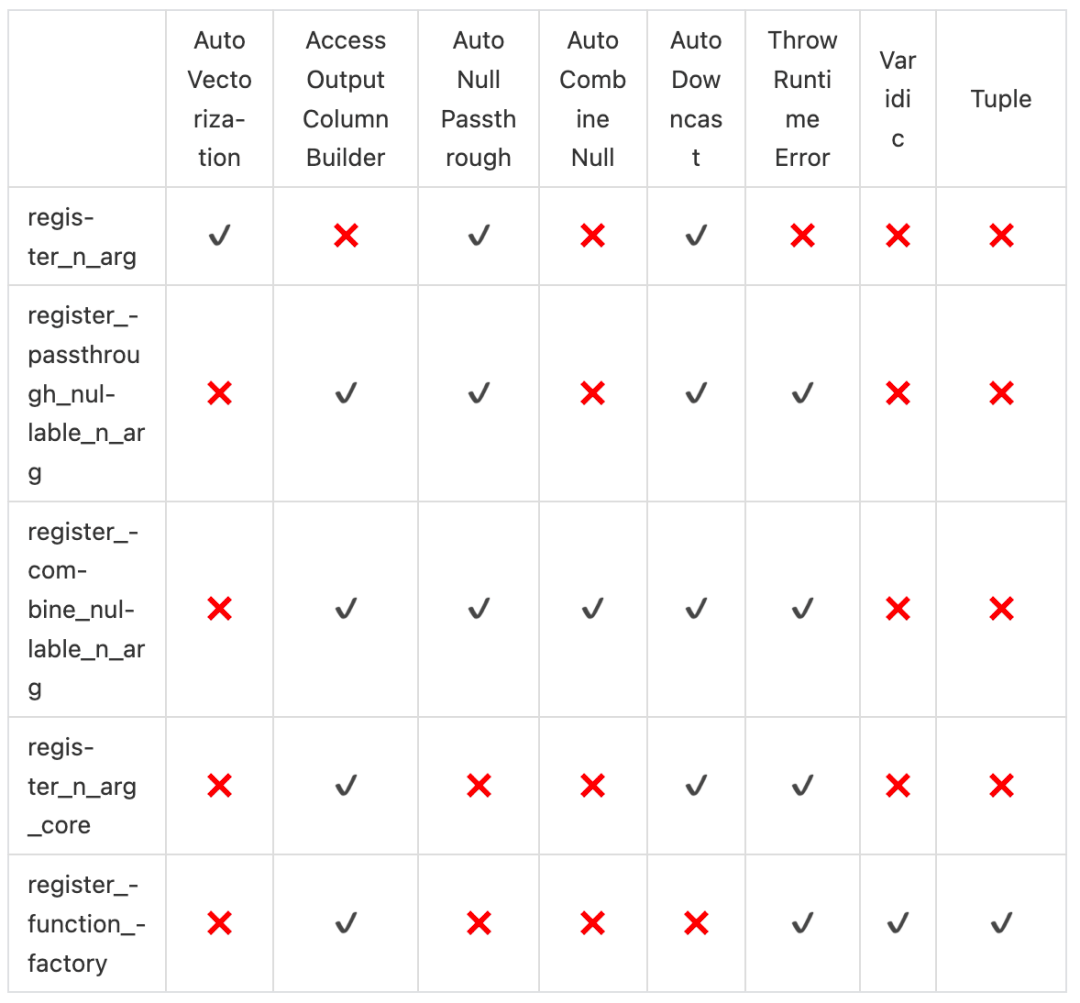
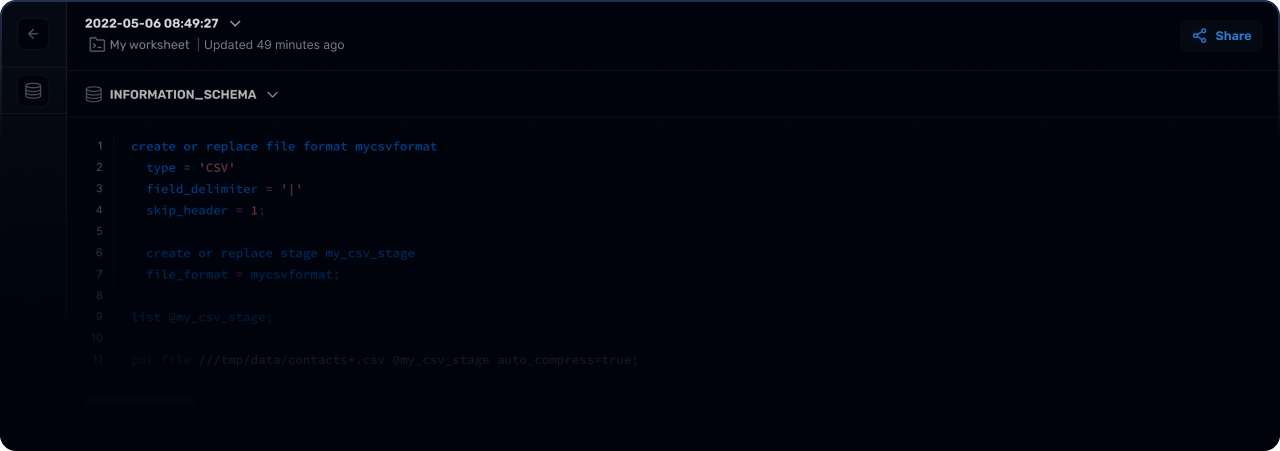
CREATE DATABASE IF NOT EXISTS abhighdb;
USE abhighdb;
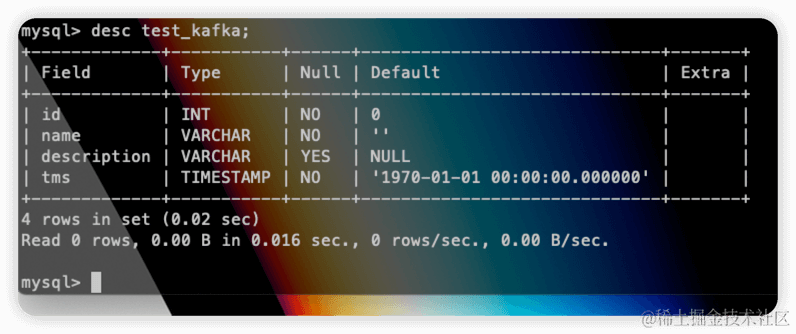
CREATE TABLE IF NOT EXISTS alumni(
alumni_id int,
first_name string,
middle_name string,
last_name string,
passing_year int,
email_address string,
phone_number string,
city string,
state_code string,
country_code string
)
STORED AS PARQUET;
INSERT INTO abhighdb.alumni VALUES
(1,"Rakesh","Rahul","Pingle",1994,"rpingle@nps.gov",9845357643,"Dhule","MH","IN"),
(2,"Abhiram","Vijay","Singh",1994,"asingh@howstuffworks.com",9987654354,"Chalisgaon","MH","IN"),
(3,"Dhriti","Anay","Rokade",1996,"drokade@theguardian.com",9087654325,"Nagardeola","MH","IN"),
(4,"Vimal","","Prasad",1995,"vprasad@cmu.edu",9876574646,"Kalwadi","MH","IN"),
(5,"Kabir","Amitesh","Shirode",1996,"kshirode@google.co.jp",9708564367,"Malegaon","MH","IN"),
(6,"Rajesh","Sohan","Reddy",1994,"rreddy@nytimes.com",8908765784,"Koppal","KA","IN"),
(7,"Swapnil","","Kumar",1994,"skumar@apache.org",8790654378,"Gurugram","HR","IN"),
(8,"Rajesh","","Shimpi",1994,"rshimpi@ucoz.ru",7908654765,"Pachora","MH","IN"),
(9,"Rakesh","Lokesh","Prasad",1993,"rprasad@facebook.com",9807564775,"Hubali","KA","IN"),
(10,"Sangam","","Mishra",1994,"smishra@facebook.com",9806564775,"Hubali","KA","IN"),
(11,"Sambhram","Akash","Attota",1994,"sattota@uol.com.br",7890678965,"Nagpur","MH","IN");
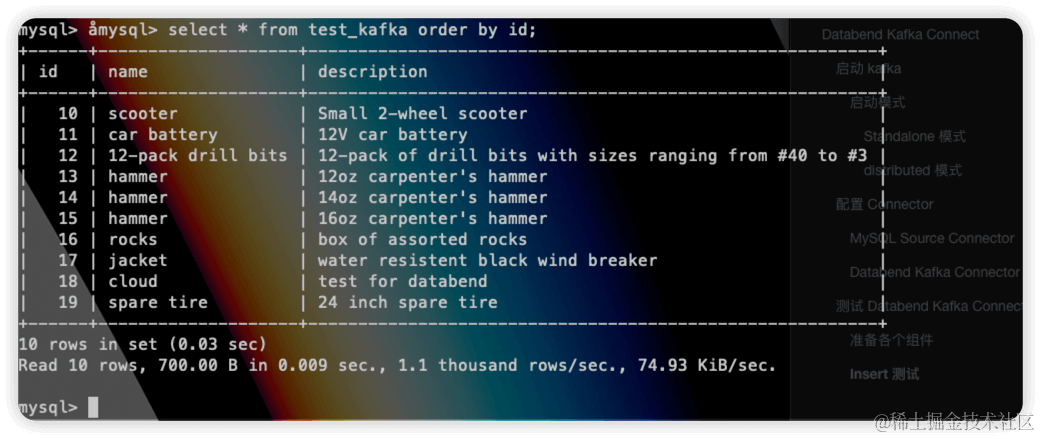
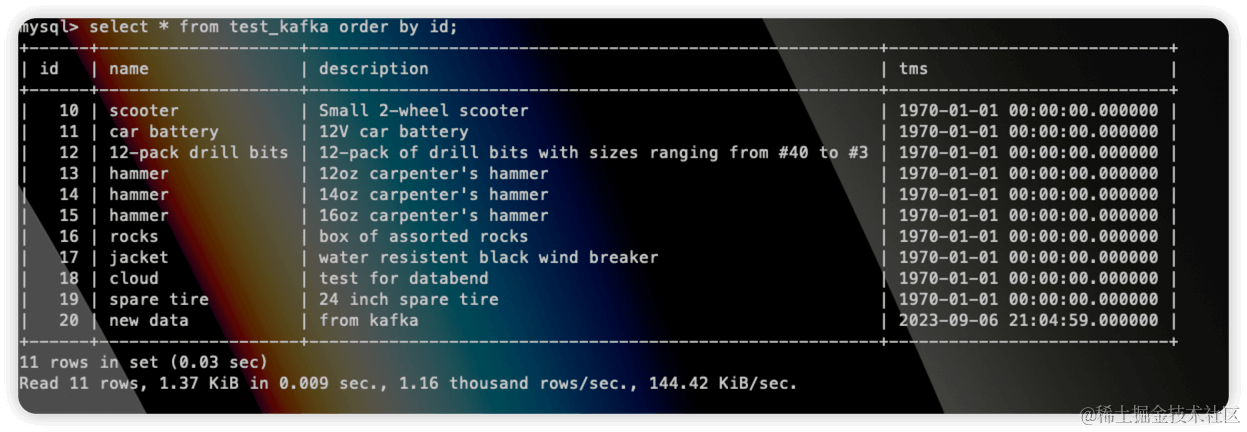
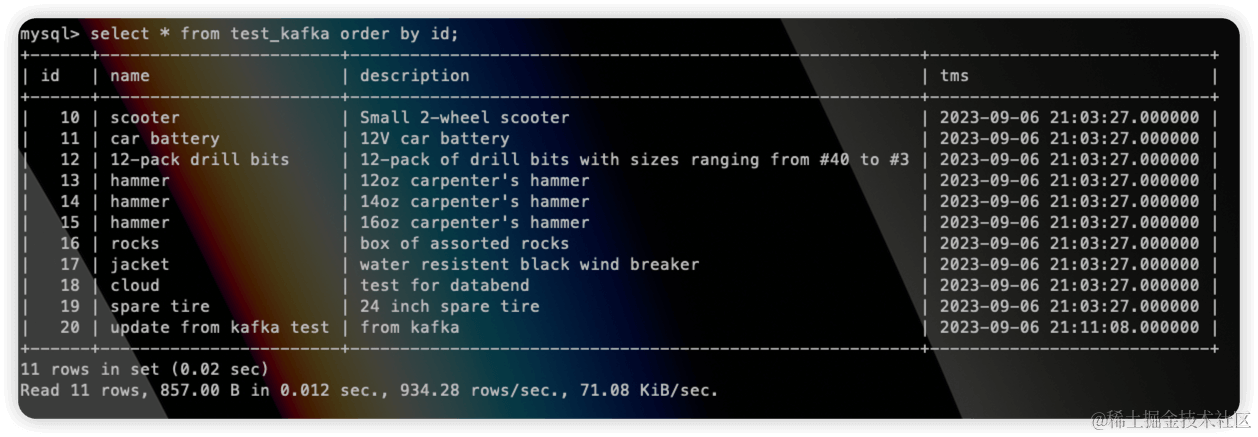
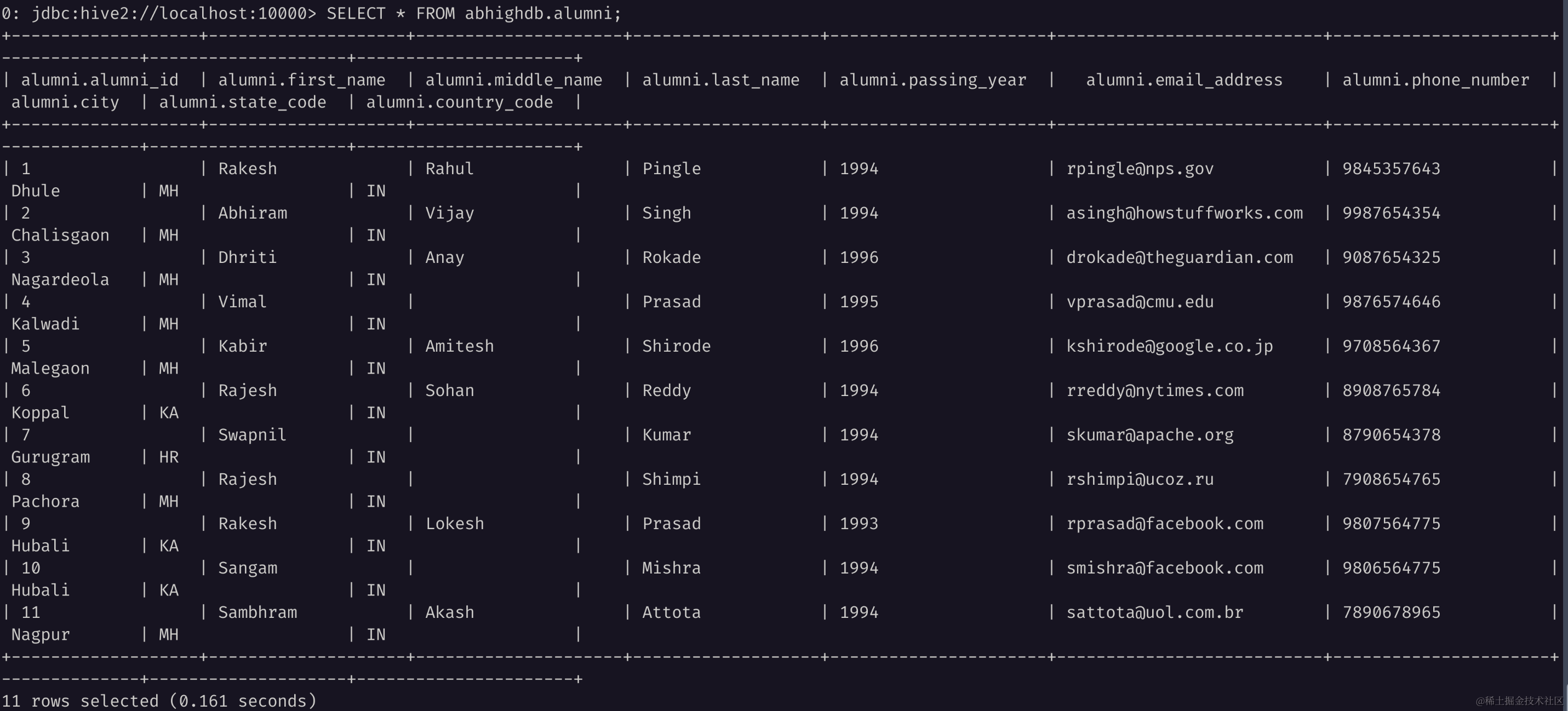
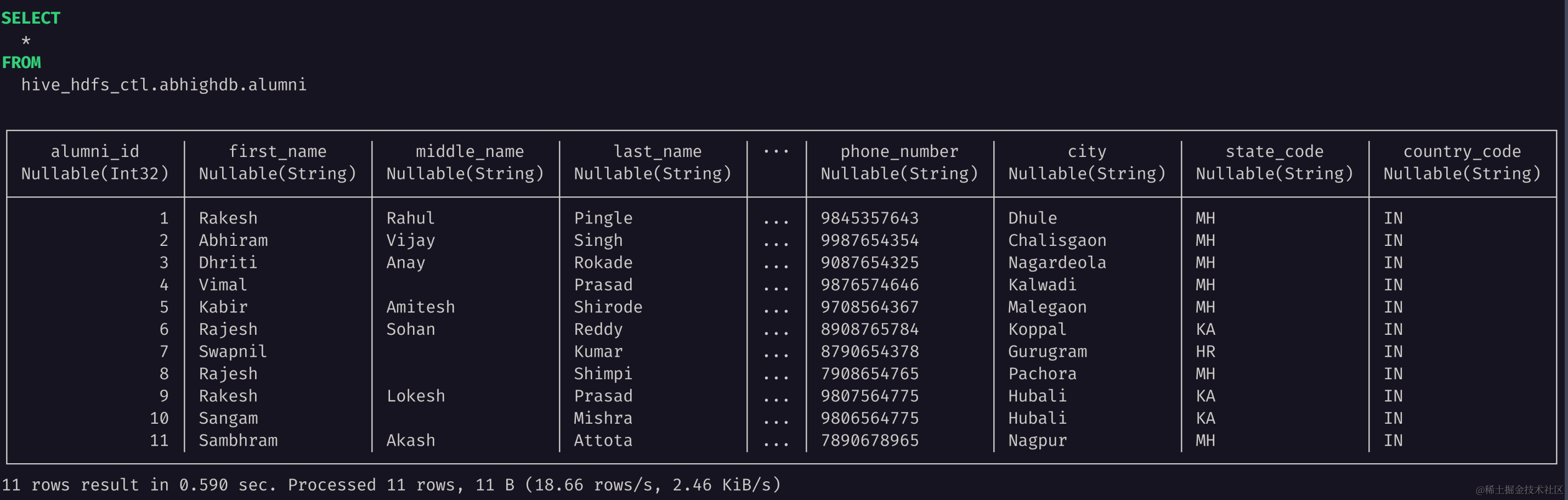
SELECT * FROM abhighdb.alumni;