




本文详细介绍如何通过 AWS DMS + S3 中转的方式,将 Amazon RDS MySQL / Aurora MySQL 的数据(全量 + 增量 CDC)同步到 Databend Cloud,实现分钟级延迟的数据湖同步方案。
为什么选择这个方案?
在实际业务中,我们经常需要将线上 MySQL 数据库的数据同步到数据湖进行分析。这套方案的核心优势在于:
- 全托管:AWS DMS 负责 binlog 解析和数据搬运,无需自建 CDC 组件
- 低延迟:端到端延迟约 1-2 分钟
- 高可靠:raw 层保留完整变更日志,支持审计和灾难恢复
- 易扩展:新增表只需重复固定步骤,无需修改整体架构
整体架构
┌─────────────────────┐
│ RDS MySQL / Aurora │
│ (源数据库) │
└────────┬────────────┘
│ Binlog
▼
┌─────────────────────┐
│ AWS DMS Task │
│ (全量 + CDC 增量) │
└────────┬────────────┘
│ Parquet 文件
▼
┌─────────────────────┐
│ Amazon S3 │
│ (中转存储,按表 │
│ 目录组织文件) │
└────────┬────────────┘
│ COPY INTO(定时任务)
▼
┌─────────────────────┐
│ Databend Cloud │
│ ┌───────────────┐ │
│ │ raw 层 │ │ ← 仅追加,保留所有变更事件
│ │ (变更日志) │ │
│ └──────┬────────┘ │
│ │ Stream + MERGE INTO(事件驱动)
│ ▼ │
│ ┌───────────────┐ │
│ │ ods 层 │ │ ← 最新状态,干净的业务表
│ │ (合并后) │ │
│ └───────────────┘ │
└─────────────────────┘
设计要点:
- raw 层:仅追加,永不更新。相当于 binlog 的完整回放缓冲区,用于审计和灾难恢复,建议至少保留 15 天后再清理。
- ods 层:最新状态的业务表,下游查询直接命中这一层。
- 事件驱动:Stream 检测到 raw 层有新数据时,才触发 MERGE INTO,避免空跑。
前置条件
| 项目 | 要求 |
|---|---|
| 源数据库 | RDS MySQL 5.7+ / Aurora MySQL 2.x 或 3.x,开启 binlog(binlog_format = ROW) |
| AWS DMS | 复制实例与源数据库在同一 VPC / Region |
| S3 存储桶 | 专用存储桶(或前缀),与源数据库同 Region |
| IAM 角色 | DMS 服务角色需具备目标存储桶的 S3 读写删除权限 |
| Databend Cloud | 活跃的 Warehouse,能创建 Stage / Task / Stream |
| 网络 | Databend Cloud 能访问 S3 存储桶(同 Region 可降低成本和延迟) |
DMS 的 IAM 角色配置
DMS 服务角色需要两部分:信任策略(谁可以 Assume 这个角色)和权限策略(角色能做什么)。
信任策略(IAM → 角色 → 信任关系):
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSDMSS3BucketPolicyTemplate",
"Effect": "Allow",
"Principal": {
"Service": "dms.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<your-aws-account-id>"
}
}
}
]
}
权限策略(IAM → 角色 → 权限 → 创建内联策略):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:DeleteObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::<your-dms-bucket>/*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::<your-dms-bucket>"
}
]
}
注意: 两条 Statement 分开是因为对象级操作(PutObject、DeleteObject、GetObject)的 Resource 需要 bucket/,而桶级操作(ListBucket、GetBucketLocation)的 Resource 是 bucket(不带 /)。如果缺少 s3:DeleteObject 权限,DMS 任务在全量加载开始时清理目标 S3 目录会失败。
第一步:创建 S3 存储桶
创建一个专用的 S3 存储桶(或在已有桶中使用专用前缀)用于 DMS 输出。
aws s3 mb s3://your-dms-bucket --region ap-southeast-1
第二步:配置 AWS DMS
2.1 创建复制实例
在 AWS DMS 控制台中:
- 进入 DMS → 复制实例 → 创建复制实例
- 配置:
- 实例类型:dms.r5.large 或更高(根据表数量和吞吐量选择)
- VPC:与源 RDS / Aurora 相同的 VPC
- 多可用区:生产环境建议开启
- 分配存储:100 GB+(DMS 在 CDC 期间使用本地磁盘作为缓冲)
2.2 创建源端点(RDS MySQL / Aurora)
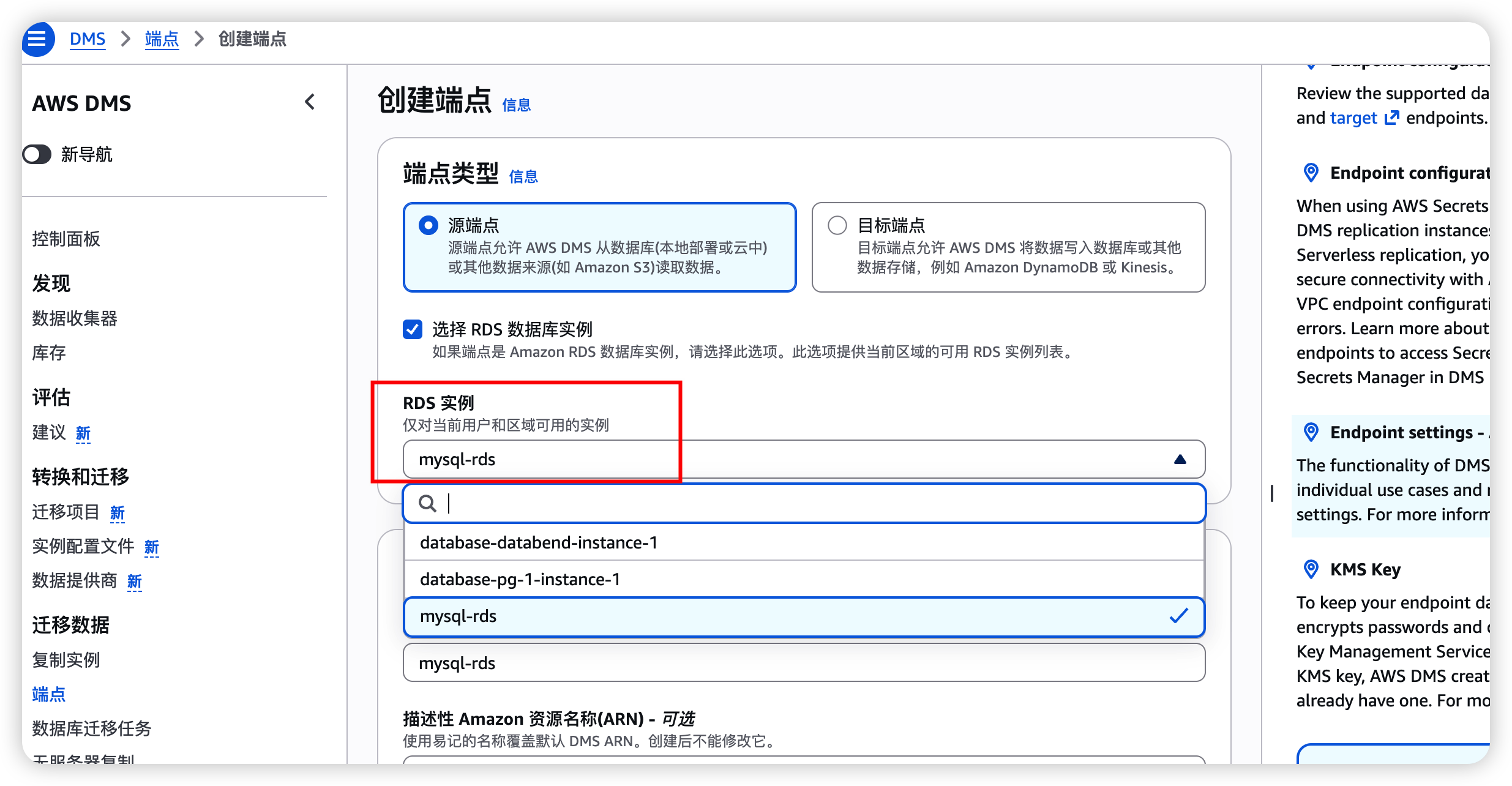
- 进入 DMS → 端点 → 创建端点
- 选择 源端点
- 配置:
| 字段 | 值 |
|---|---|
| 端点类型 | Source |
| 引擎 | MySQL(RDS MySQL 和 Aurora MySQL 都选这个) |
| 服务器名称 | RDS / Aurora 端点地址(如 mydb.cluster-xxxx.ap-southeast-1.rds.amazonaws.com) |
| 端口 | 3306 |
| 用户名 | DMS 复制专用用户(见下方) |
| 密码 | 复制用户的密码 |
| SSL 模式 | 生产环境建议 verify-ca |
在源数据库上创建专用复制用户:
CREATE USER 'dms_user'@'%' IDENTIFIED BY 'your_secure_password';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'dms_user'@'%';
-- Aurora 还需要额外授权:
GRANT EXECUTE ON PROCEDURE mysql.rds_set_configuration TO 'dms_user'@'%';
FLUSH PRIVILEGES;
确保 binlog 保留时间(Aurora / RDS MySQL 通用):
-- 设置 binlog 保留 24 小时(根据需要调整)
CALL mysql.rds_set_configuration('binlog retention hours', 24);
验证方式:执行 SHOW BINARY LOGS; 确认日志存在且未被过早清理。
2.3 创建目标端点(S3)
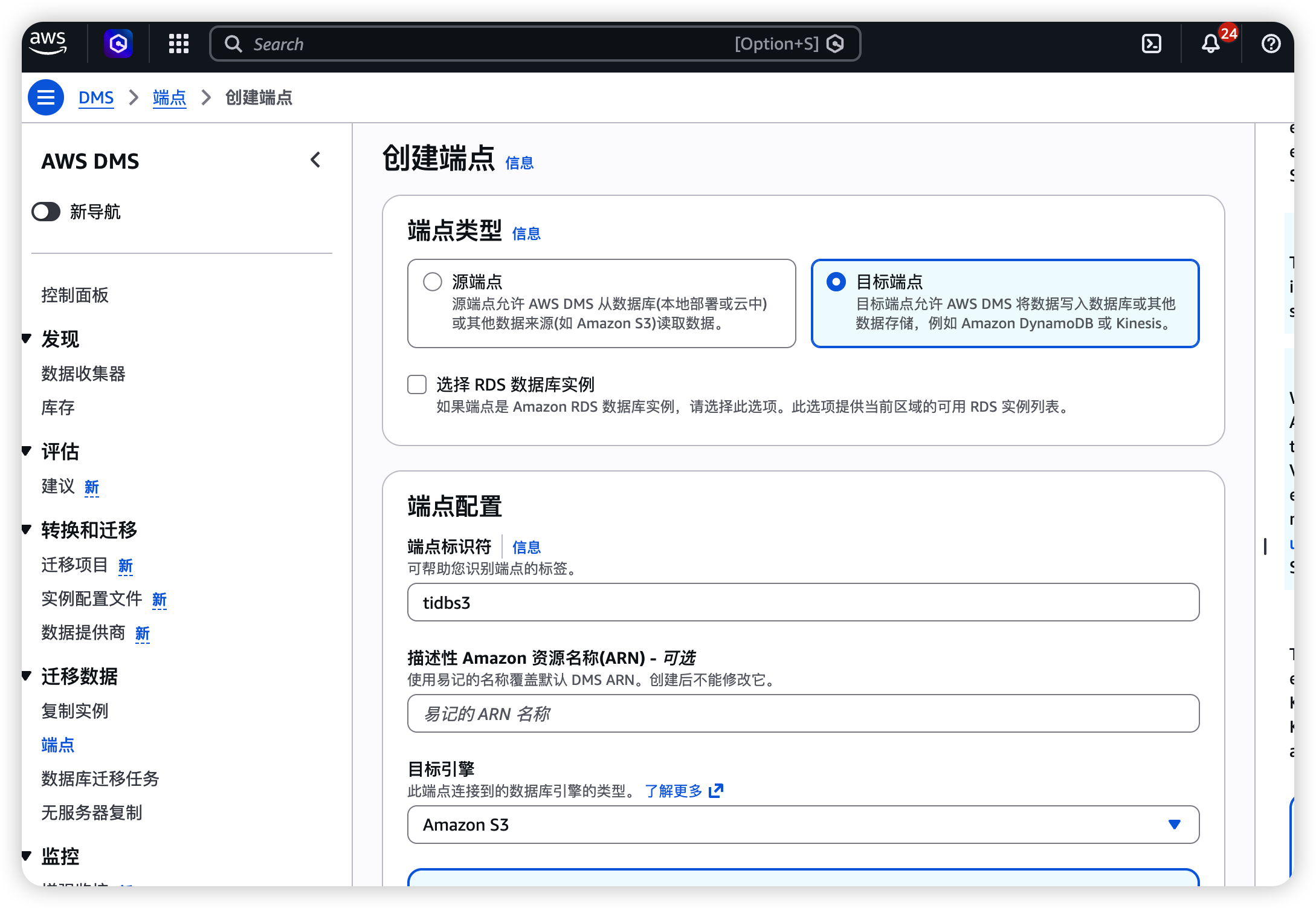
- 进入 DMS → 端点 → 创建端点
- 选择 目标端点
- 配置:
| 字段 | 值 |
|---|---|
| 端点类型 | Target |
| 引擎 | Amazon S3 |
| 服务访问角色 ARN | 具有 S3 写权限的 IAM 角色 ARN |
| 存储桶名称 | your-dms-bucket |
| 存储桶文件夹 | aurora/(或你偏好的前缀) |
| 数据格式 | Parquet |
额外连接属性(粘贴到"额外连接属性"字段):
dataFormat=parquet;parquetVersion=PARQUET_2_0;timestampColumnName=_dms_ingestion_timestamp;includeOpForFullLoad=true;cdcInsertsAndUpdates=true;addColumnName=true;
各参数说明:
| 参数 | 值 | 用途 |
|---|---|---|
| dataFormat | parquet | 输出 Parquet 格式(压缩率高,带 schema) |
| parquetVersion | PARQUET_2_0 | 使用 Parquet v2,类型支持更好 |
| timestampColumnName | _dms_ingestion_timestamp | 为每行添加摄入时间戳列 |
| includeOpForFullLoad | true | 全量加载行也添加 Op 列(值为 I),保持 raw 层 schema 一致 |
| cdcInsertsAndUpdates | true | CDC 输出包含 INSERT 和 UPDATE |
| addColumnName | true | Parquet 元数据中包含列名 |
2.4 创建 DMS 迁移任务
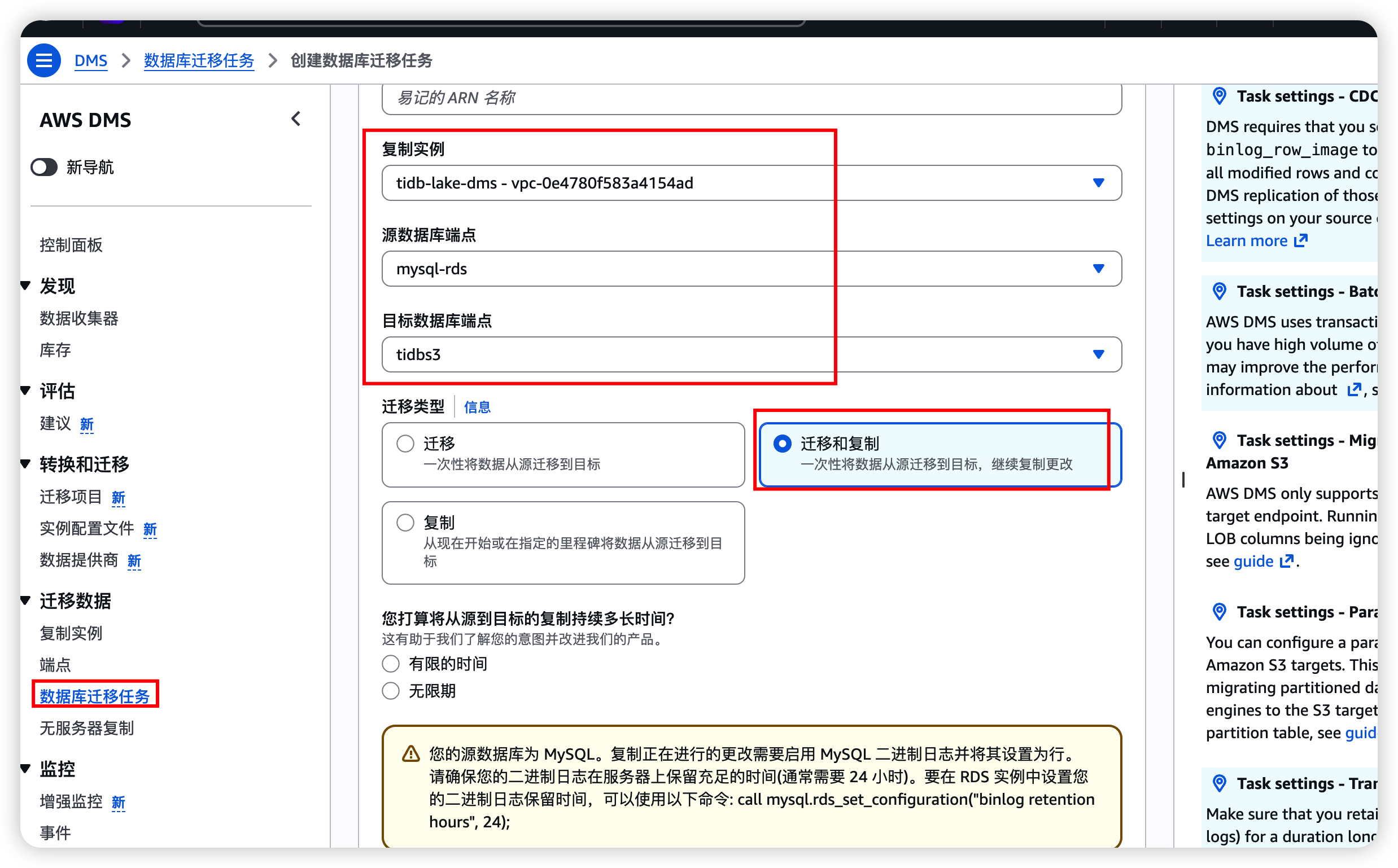
- 进入 DMS → 数据库迁移任务 → 创建任务
- 配置:
| 字段 | 值 |
|---|---|
| 任务标识符 | aurora-to-s3-full-cdc |
| 复制实例 | 选择 2.1 中创建的实例 |
| 源端点 | 选择 2.2 中的 MySQL 源端点 |
| 目标端点 | 选择 2.3 中的 S3 目标端点 |
| 迁移类型 | 迁移现有数据并复制持续更改(全量 + CDC) |
- 表映射 — 使用 JSON 编辑器,同步某个 schema 下的所有表:
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "sync-all-tables",
"object-locator": {
"schema-name": "db",
"table-name": "%"
},
"rule-action": "include"
}
]
}
将 db 替换为你的实际 schema 名。% 匹配所有表,也可以指定具体表名。
- 任务设置 — 完整配置(关键参数已标注):
{
"TargetMetadata": {
"TargetSchema": "",
"SupportLobs": true,
"FullLobMode": false,
"LobChunkSize": 32,
"LimitedSizeLobMode": true,
"LobMaxSize": 32,
"InlineLobMaxSize": 0,
"LoadMaxFileSize": 0,
"ParallelLoadThreads": 0,
"ParallelLoadBufferSize": 0,
"BatchApplyEnabled": false,
"TaskRecoveryTableEnabled": false,
"ParallelLoadQueuesPerThread": 0,
"ParallelApplyThreads": 0,
"ParallelApplyBufferSize": 0,
"ParallelApplyQueuesPerThread": 0
},
"FullLoadSettings": {
"CreatePkAfterFullLoad": false,
"StopTaskCachedChangesApplied": false,
"StopTaskCachedChangesNotApplied": false,
"MaxFullLoadSubTasks": 8,
"TransactionConsistencyTimeout": 600,
"CommitRate": 10000
},
"Logging": {
"EnableLogging": true,
"EnableLogContext": false,
"LogComponents": [
{ "Id": "SOURCE_UNLOAD", "Severity": "LOGGER_SEVERITY_DEFAULT" },
{ "Id": "SOURCE_CAPTURE", "Severity": "LOGGER_SEVERITY_DEFAULT" },
{ "Id": "TARGET_LOAD", "Severity": "LOGGER_SEVERITY_DEFAULT" },
{ "Id": "TARGET_APPLY", "Severity": "LOGGER_SEVERITY_DEFAULT" },
{ "Id": "TASK_MANAGER", "Severity": "LOGGER_SEVERITY_DEFAULT" }
],
"CloudWatchLogGroup": null,
"CloudWatchLogStream": null
},
"ControlTablesSettings": {
"ControlSchema": "",
"HistoryTimeslotInMinutes": 5,
"HistoryTableEnabled": false,
"SuspendedTablesTableEnabled": false,
"StatusTableEnabled": false
},
"StreamBufferSettings": {
"StreamBufferCount": 3,
"StreamBufferSizeInMB": 8,
"CtrlStreamBufferSizeInMB": 5
},
"ChangeProcessingDdlHandlingPolicy": {
"HandleSourceTableDropped": true,
"HandleSourceTableTruncated": true,
"HandleSourceTableAltered": true
},
"ErrorBehavior": {
"DataErrorPolicy": "LOG_ERROR",
"DataTruncationErrorPolicy": "LOG_ERROR",
"DataErrorEscalationPolicy": "SUSPEND_TABLE",
"DataErrorEscalationCount": 0,
"TableErrorPolicy": "SUSPEND_TABLE",
"TableErrorEscalationPolicy": "STOP_TASK",
"TableErrorEscalationCount": 0,
"RecoverableErrorCount": -1,
"RecoverableErrorInterval": 5,
"RecoverableErrorThrottling": true,
"RecoverableErrorThrottlingMax": 1800,
"RecoverableErrorStopRetryAfterThrottlingMax": false,
"ApplyErrorDeletePolicy": "IGNORE_RECORD",
"ApplyErrorInsertPolicy": "LOG_ERROR",
"ApplyErrorUpdatePolicy": "LOG_ERROR",
"ApplyErrorEscalationPolicy": "LOG_ERROR",
"ApplyErrorEscalationCount": 0,
"ApplyErrorFailOnTruncationDdl": false,
"FullLoadIgnoreConflicts": true,
"FailOnTransactionConsistencyBreached": false,
"FailOnNoTablesCaptured": true
},
"ChangeProcessingTuning": {
"BatchApplyPreserveTransaction": true,
"BatchApplyTimeoutMin": 1,
"BatchApplyTimeoutMax": 30,
"BatchApplyMemoryLimit": 500,
"BatchSplitSize": 0,
"MinTransactionSize": 1000,
"CommitTimeout": 1,
"MemoryLimitTotal": 1024,
"MemoryKeepTime": 60,
"StatementCacheSize": 50
},
"ValidationSettings": {
"EnableValidation": false,
"ValidationMode": "ROW_LEVEL",
"ThreadCount": 5,
"FailureMaxCount": 10000,
"TableFailureMaxCount": 1000,
"HandleCollationDiff": false,
"ValidationOnly": false,
"RecordFailureDelayLimitInMinutes": 0,
"SkipLobColumns": false,
"ValidationPartialLobSize": 0,
"ValidationQueryCdcDelaySeconds": 0,
"PartitionSize": 10000
},
"PostProcessingRules": null,
"CharacterSetSettings": null,
"LoopbackPreventionSettings": null,
"BeforeImageSettings": null,
"FailTaskWhenCleanTaskResourceFailed": false
}
关键配置说明:
| 配置项 | 值 | 说明 |
|---|---|---|
| BatchApplyEnabled | false | 关键! 必须为 false,DMS 才会在 Parquet 中写入逐行的 Op 列(I/U/D)。设为 true 会导致 Op 列缺失或不正确 |
| EnableLogging | true | 开启 CloudWatch 日志,方便排查问题 |
| MaxFullLoadSubTasks | 8 | 全量加载的并行线程数,表多时可调大 |
| HandleSourceTableAltered | true | 自动处理源端 DDL 变更(加列、删列等) |
| TableErrorPolicy | SUSPEND_TABLE | 出错时只挂起出错的表,不影响整个任务 |
| RecoverableErrorCount | -1 | 可恢复错误(网络抖动、限流等)无限重试 |
| FullLoadIgnoreConflicts | true | 全量加载时跳过重复键错误(S3 目标安全) |
| LimitedSizeLobMode | true | LOB 截断为 32KB 以提升性能。如有大文本/Blob 列,需调大 LobMaxSize |
- 在 S3 目标端点的额外连接属性中,设置 CDC 调优参数:
| 参数 | 值 | 用途 |
|---|---|---|
| cdcMinFileSize | 32(KB) | 降低阈值,更快将小文件刷到 S3 |
| cdcMaxBatchInterval | 30(秒) | CDC 文件刷到 S3 的最大间隔 |
DMS CDC 端到端延迟通常在 30-60 秒。这是 DMS 的设计权衡,不是 Databend Cloud 的瓶颈,可以根据实时性要求调整此参数。
- 点击 创建任务。任务会自动开始全量加载,完成后自动切换到 CDC 模式。
2.5 S3 落地目录结构
DMS 会自动按 schema 和表名组织文件:
s3://dms-databend-bucket/
├── databend/
│ ├── orders/
│ │ ├── 20260416-124049492.parquet ← 全量加载文件
│ │ └── 20260416-124049752.parquet
│ ├── table_b/
│ │ ├── 20260416-xxxxxxxxx.parquet
│ │ └── ...
│ └── ...
CDC Parquet 文件中 DMS 自动添加的列:
| 列名 | 类型 | 说明 |
|---|---|---|
| Op | STRING | 操作类型:I(Insert)、U(Update)、D(Delete) |
| _dms_ingestion_timestamp | TIMESTAMP | DMS 捕获该变更的时间 |
| (所有源表列) | (原始类型) | 业务数据列 |
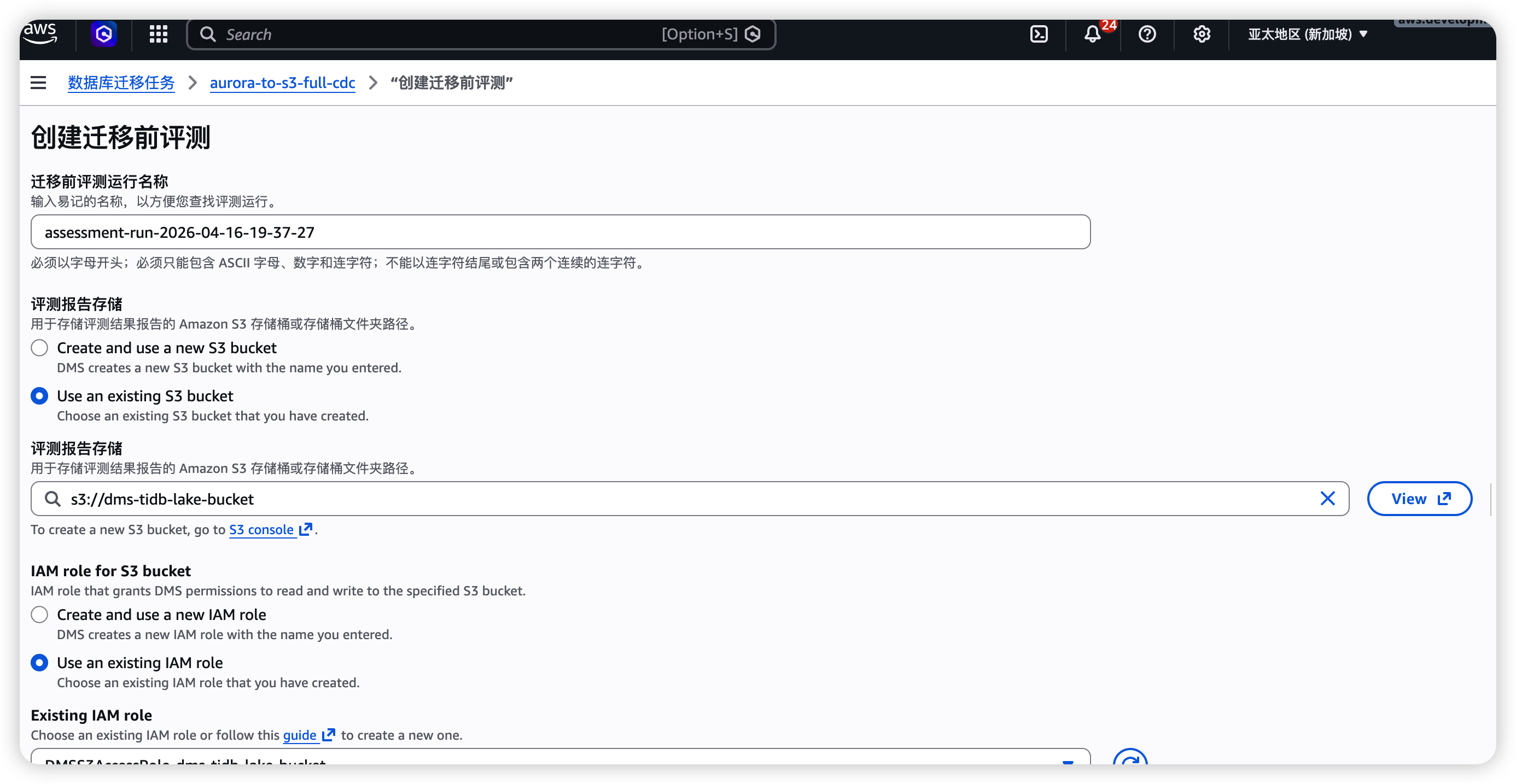
第三步:配置 Databend Cloud
3.1 创建指向 S3 的外部 Stage
-- 方式 A:使用 Access Key / Secret Key
CREATE STAGE IF NOT EXISTS dms_s3_stage
URL = 's3://dms-databend-bucket/databend/'
CONNECTION = (
AWS_KEY_ID = '<your-access-key>',
AWS_SECRET_KEY = '<your-secret-key>',
REGION = 'ap-southeast-1'
);
-- 方式 B:使用 IAM Role ARN(生产环境推荐)
CREATE STAGE IF NOT EXISTS dms_s3_stage
URL = 's3://dms-databend-bucket/databend/'
CONNECTION = (
ROLE_ARN = 'arn:aws:iam::123456789012:role/databend-s3-access',
REGION = 'ap-southeast-1'
);
验证 Stage 能否列出文件:
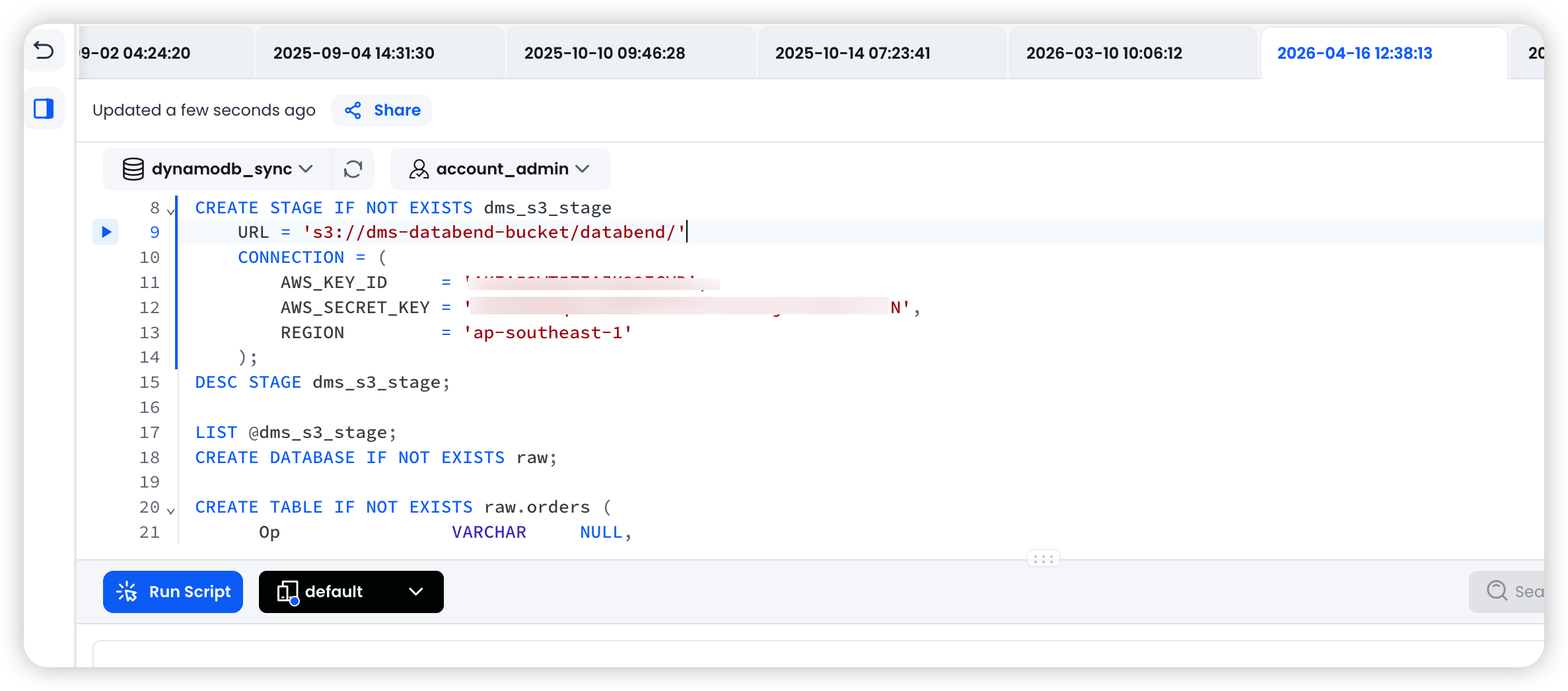
LIST @dms_s3_stage;
3.2 创建 raw 层表
raw 层原样存储 DMS Parquet 文件中的所有变更事件,每张源表对应一张 raw 表。
设计要点:
- 保留所有原始业务列 + DMS 元数据列(Op、_dms_ingestion_timestamp)
- 开启 ENABLE_SCHEMA_EVOLUTION,源端新增列时自动同步
- 这一层只追加,永不更新或删除
示例:源表 orders
CREATE DATABASE IF NOT EXISTS raw;
CREATE TABLE IF NOT EXISTS raw.orders (
-- DMS 元数据列
Op VARCHAR NULL,
_dms_ingestion_timestamp TIMESTAMP NULL,
-- 业务列(与源表 schema 一致)
order_id BIGINT NULL,
user_id BIGINT NULL,
product_id BIGINT NULL,
quantity INT NULL,
amount DECIMAL(12,2) NULL,
status VARCHAR NULL,
created_at TIMESTAMP NULL,
updated_at TIMESTAMP NULL
) ENABLE_SCHEMA_EVOLUTION = true;
每张源表都需要重复此步骤。列名必须与 Parquet 文件中的列名完全一致。
3.3 创建 ods 层表
ods 层保存每条记录的最新状态,是下游查询直接使用的干净业务表。
CREATE DATABASE IF NOT EXISTS ods;
CREATE TABLE IF NOT EXISTS ods.orders (
order_id BIGINT NOT NULL,
user_id BIGINT NULL,
product_id BIGINT NULL,
quantity INT NULL,
amount DECIMAL(12,2) NULL,
status VARCHAR NULL,
is_deleted BOOLEAN NOT NULL DEFAULT false, -- 软删除标记
created_at TIMESTAMP NULL,
updated_at TIMESTAMP NULL
);
使用软删除(is_deleted 标记)而非物理 DELETE。这样可以保留历史记录,避免因 binlog 中的 D 操作导致数据丢失。
第四步:全量数据加载
全量加载文件落在 s3://dms-databend-bucket/databend/orders/ 下。先加载到 raw 层,再合并到 ods 层。
4.1 将全量文件加载到 raw 层
COPY INTO raw.orders
FROM @dms_s3_stage/orders/
PATTERN = '.*\.parquet'
FILE_FORMAT = (TYPE = PARQUET)
PURGE = TRUE;
4.2 初始合并到 ods 层
全量加载阶段所有行的 Op = 'I',直接 INSERT 即可:
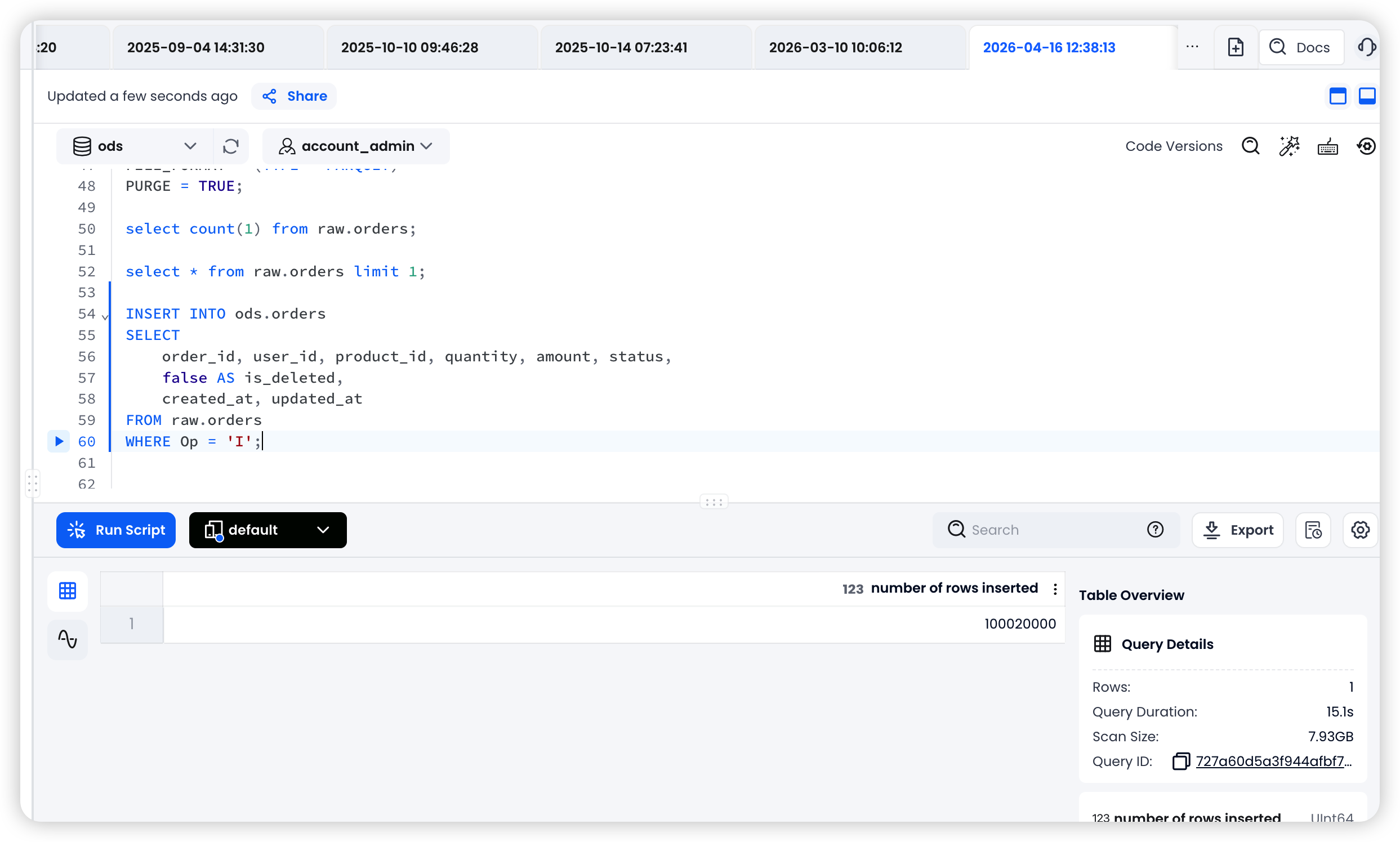
INSERT INTO ods.orders
SELECT
order_id, user_id, product_id, quantity, amount, status,
false AS is_deleted,
created_at, updated_at
FROM raw.orders
WHERE Op = 'I';
全量加载完成、ods 层数据就绪后,继续第五步设置 CDC 增量管道。
第五步:设置 CDC 增量同步管道
5.1 在 raw 层表上创建 Stream
Stream 会追踪 raw 表中新追加的行。当 MERGE INTO 任务消费 Stream 后,游标自动前移。
CREATE STREAM IF NOT EXISTS raw.stream_orders
ON TABLE raw.orders
APPEND_ONLY = TRUE;
5.2 创建任务 1 — COPY INTO raw 层(定时调度)
该任务定时轮询 S3 中的新 CDC Parquet 文件,加载到 raw 表。可以按业务域将多张表合并到一个任务中。
-- 单表任务示例
CREATE TASK load_orders_raw
WAREHOUSE = 'default'
SCHEDULE = 1 MINUTE
SUSPEND_TASK_AFTER_NUM_FAILURES = 3
AS
COPY INTO raw.orders
FROM @dms_s3_stage/orders/
PATTERN = '.*\.parquet'
FILE_FORMAT = (TYPE = PARQUET)
PURGE = TRUE
ON_ERROR = CONTINUE;
多表任务示例(按业务域分组):
CREATE TASK load_databend_domain_raw
WAREHOUSE = 'default'
SCHEDULE = 1 MINUTE
SUSPEND_TASK_AFTER_NUM_FAILURES = 3
AS
BEGIN
COPY INTO raw.orders
FROM @dms_s3_stage/orders/
PATTERN = '.*\.parquet'
FILE_FORMAT = (TYPE = PARQUET)
PURGE = TRUE
ON_ERROR = CONTINUE;
-- 同域的其他表在此追加 ...
END;
PURGE = TRUE 会在成功加载后删除 S3 文件,防止重复摄入。
5.3 创建任务 2 — MERGE INTO ods 层(事件驱动)
该任务在任务 1 完成后触发,且仅当 Stream 中有新数据时才执行。
关键点:QUALIFY ROW_NUMBER() = 1 去重逻辑。 在同一个 CDC 批次中,同一主键可能出现多次(比如连续两次 UPDATE)。必须只保留每个主键的最新变更,否则 MERGE 结果不确定。
CREATE TASK merge_orders
WAREHOUSE = 'default'
AFTER 'load_orders_raw'
SUSPEND_TASK_AFTER_NUM_FAILURES = 3
AS
MERGE INTO ods.orders AS target
USING (
SELECT * FROM (
SELECT
order_id,
user_id,
product_id,
quantity,
amount,
status,
created_at,
updated_at,
Op AS _op,
_dms_ingestion_timestamp AS _ts
FROM raw.stream_orders
)
QUALIFY ROW_NUMBER() OVER (
PARTITION BY order_id
ORDER BY _ts DESC
) = 1
) AS source
ON target.order_id = source.order_id
WHEN MATCHED AND source._op = 'D' THEN
UPDATE SET target.is_deleted = true, target.updated_at = source.updated_at
WHEN MATCHED AND source._op IN ('U', 'I') THEN
UPDATE SET
target.user_id = source.user_id,
target.product_id = source.product_id,
target.quantity = source.quantity,
target.amount = source.amount,
target.status = source.status,
target.is_deleted = false,
target.created_at = source.created_at,
target.updated_at = source.updated_at
WHEN NOT MATCHED AND source._op != 'D' THEN
INSERT (order_id, user_id, product_id, quantity, amount, status, is_deleted, created_at, updated_at)
VALUES (source.order_id, source.user_id, source.product_id, source.quantity,
source.amount, source.status, false, source.created_at, source.updated_at);
MERGE 逻辑说明:
| 条件 | 动作 | 场景 |
|---|---|---|
| MATCHED + Op='D' | 软删除(is_deleted = true) | 源端行被删除 |
| MATCHED + Op='U'/'I' | 更新所有列,重置 is_deleted = false | 源端行被更新(或删除后重新插入) |
| NOT MATCHED + Op!='D' | 插入新行 | ods 中不存在的新行 |
5.4 启动任务
先启动子任务,再启动父任务。 确保下游任务就绪后,上游任务才开始产生数据。
-- 第 1 步:启动子任务(MERGE)
ALTER TASK merge_orders RESUME;
-- 第 2 步:启动父任务(COPY INTO)
ALTER TASK load_orders_raw RESUME;
新增表时,重复步骤 3.2 → 3.3 → 5.1 → 5.2 → 5.3 → 5.4 即可。
第六步:验证
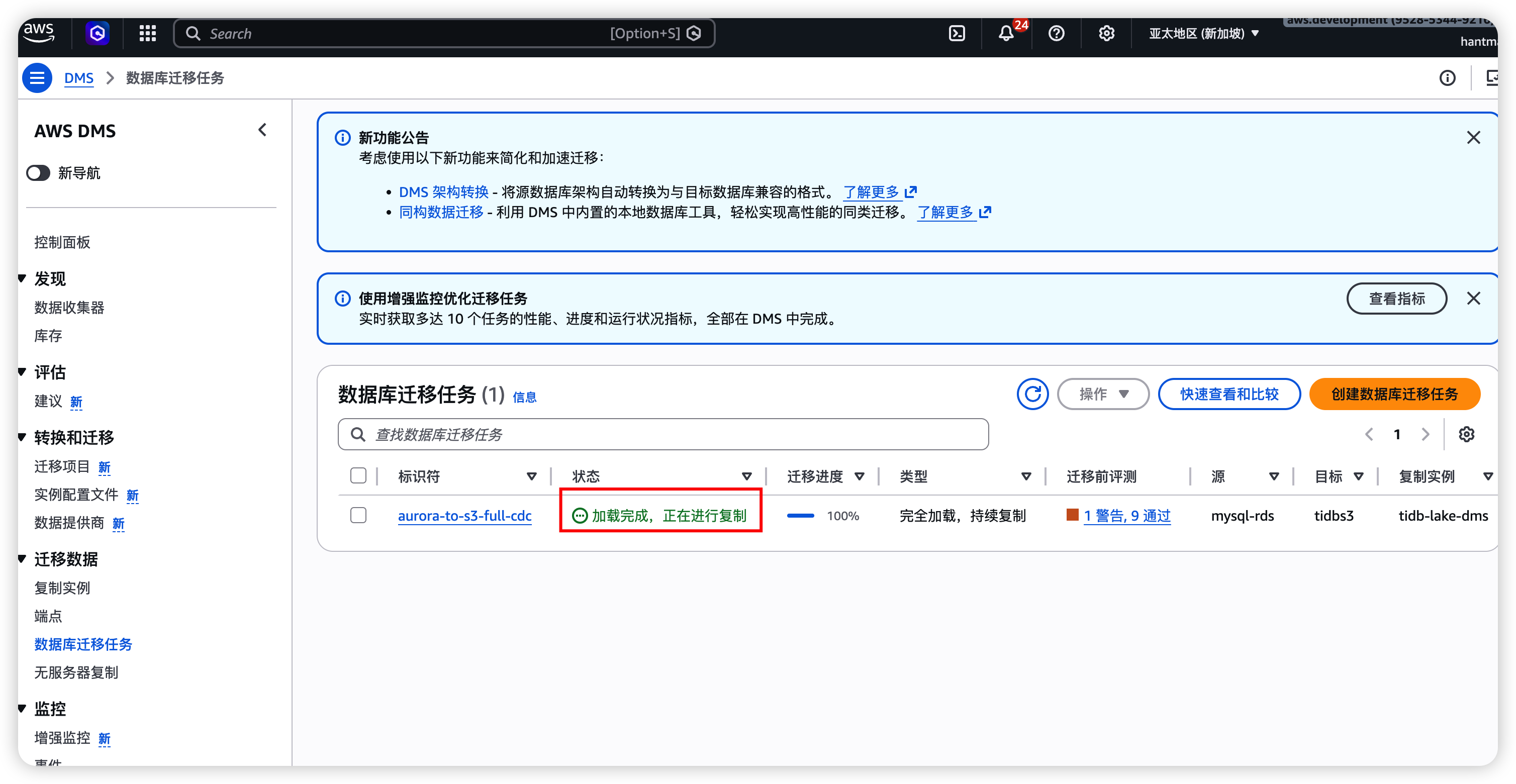
6.1 验证 DMS 任务状态
在 AWS DMS 控制台检查:
- 任务状态为 Running(全量加载完成后显示 Load complete, replication ongoing)
- 表统计 标签页显示已加载行数和 CDC 变更数
- CloudWatch 日志 中无报错
# CLI 检查
aws dms describe-table-statistics \
--replication-task-arn <your-task-arn> \
--query 'TableStatistics[*].{Table:TableName,Inserts:Inserts,Updates:Updates,Deletes:Deletes,FullLoad:FullLoadRows}'
6.2 验证 S3 文件
# 检查文件是否落地
aws s3 ls s3://dms-databend-bucket//orders/ --recursive
6.3 验证 Databend Cloud 任务
-- 查看任务状态
SHOW TASKS;
-- 查看任务执行历史
SELECT *
FROM TABLE(TASK_HISTORY())
ORDER BY scheduled_time DESC
LIMIT 20;
-- 验证 raw 层数据
SELECT COUNT(*) FROM raw.orders;
SELECT * FROM raw.orders ORDER BY _dms_ingestion_timestamp DESC LIMIT 10;
-- 验证 ods 层数据
SELECT COUNT(*) FROM ods.orders WHERE is_deleted = false;
SELECT * FROM ods.orders ORDER BY updated_at DESC LIMIT 10;
-- 检查 Stream 状态(成功合并后应为空)
SELECT COUNT(*) FROM raw.stream_orders;
6.4 端到端验证
在源数据库上依次执行以下测试操作,每步之间等待 2-3 分钟,让 DMS CDC 刷到 S3 并由 Databend Cloud 任务消费。
第 1 步:INSERT — 在源 RDS MySQL / Aurora 上执行
INSERT INTO db.orders (user_id, product_id, quantity, amount, status, created_at, updated_at)
VALUES (99999, 88888, 3, 4.4, 'pending', NOW(), NOW());
-- 记录自动生成的 order_id,后续步骤会用到
SELECT LAST_INSERT_ID();
在 Databend Cloud 上验证(等待 2-3 分钟):
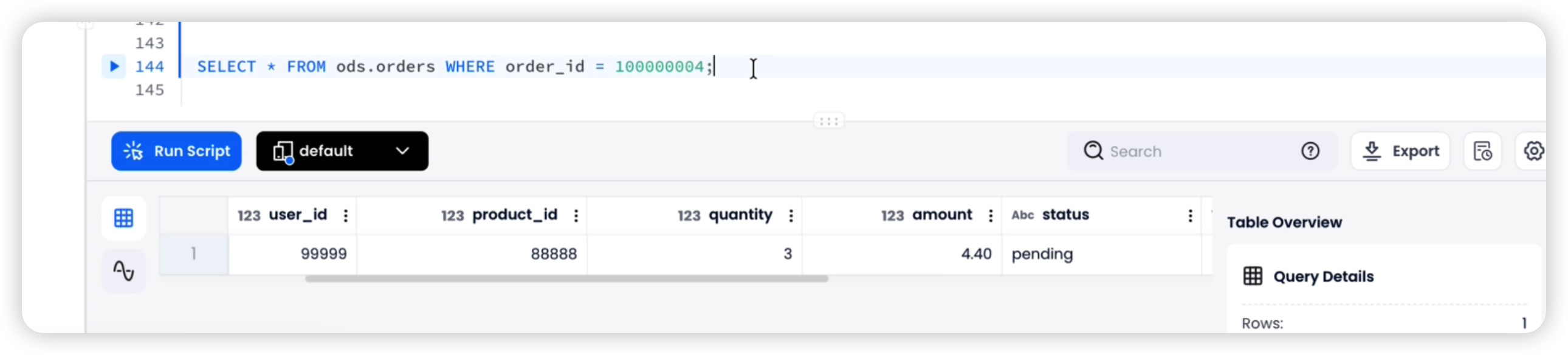
SELECT * FROM ods.orders WHERE order_id = 100000004;
-- 预期:status = 'pending', amount = 4.4, is_deleted = false
第 2 步:UPDATE — 在源 RDS MySQL / Aurora 上执行
UPDATE db.orders
SET status = 'paid', amount = 2.2, updated_at = NOW()
WHERE order_id = 100000004;
在 Databend Cloud 上验证(等待 2-3 分钟):
SELECT * FROM ods.orders WHERE order_id = 100000004;
-- 预期:status = 'paid', amount = 2.2, is_deleted = false
第 3 步:DELETE — 在源 RDS MySQL / Aurora 上执行
DELETE FROM db.orders WHERE order_id = 100000004;
在 Databend Cloud 上验证(等待 2-3 分钟):
SELECT * FROM ods.orders WHERE order_id = 100000004;
-- 预期:is_deleted = true
清理测试数据:
DELETE FROM ods.orders WHERE order_id = 100000004;
DELETE FROM raw.orders WHERE order_id = 100000004;
第七步:运维管理
7.1 常用操作
-- 暂停任务(先停父任务,再停子任务)
ALTER TASK load_orders_raw SUSPEND;
ALTER TASK merge_orders SUSPEND;
-- 恢复任务(先启子任务,再启父任务)
ALTER TASK merge_orders RESUME;
ALTER TASK load_orders_raw RESUME;
-- 手动触发任务(调试用)
EXECUTE TASK load_orders_raw;
-- 查看未消费的 Stream 数据
SELECT * FROM raw.stream_orders LIMIT 10;
7.2 raw 层数据清理
raw 层会持续增长,建议设置定时清理任务(至少保留 15 天):
-- 手动清理
DELETE FROM raw.orders
WHERE _dms_ingestion_timestamp < DATEADD(DAY, -15, NOW());
-- 或创建定时清理任务
CREATE TASK cleanup_raw_orders
WAREHOUSE = 'default'
SCHEDULE = USING CRON '0 3 * * *' -- 每天凌晨 3 点执行
AS
DELETE FROM raw.orders
WHERE _dms_ingestion_timestamp < DATEADD(DAY, -15, NOW());
ALTER TASK cleanup_raw_orders RESUME;
常见踩坑与解决方案
| 问题 | 表现 | 解决方案 |
|---|---|---|
| 缺少 QUALIFY ROW_NUMBER() 去重 | ods 层数据脏/不一致 | MERGE 的 USING 子查询中必须按主键去重,只保留每个 key 的最新变更 |
| 物理 DELETE 而非软删除 | 历史数据丢失,无法审计 | ods 层使用 is_deleted 标记;Op='D' 时设置标记而非删除行 |
| 跳过 raw 层直接写 ods | 无法回放或从错误合并中恢复 | 始终保留 raw 层作为数据源头,至少保留 15 天 |
| DDL 变更未同步 | COPY INTO 解析新 Parquet 列失败 | raw 表开启 ENABLE_SCHEMA_EVOLUTION = true;ods 表手动添加新列 |
| 时区不一致 | 源端和 Databend Cloud 的 updated_at 值不匹配 | DMS 默认使用 UTC;确保源数据库也使用 UTC,或显式处理时区转换 |
| 字符集问题 | Databend Cloud 中出现乱码 | 确保源数据库使用 UTF-8;Parquet 格式下 DMS 自动处理编码 |
| BatchApplyEnabled = true | CDC 文件中 Op 列缺失或不正确 | DMS 任务设置中将 BatchApplyEnabled 设为 false |
| S3 文件未被清理 | raw 层出现重复数据 | 确保 COPY INTO 中设置 PURGE = TRUE;检查 IAM 是否有 s3:DeleteObject 权限 |
| 全量加载和 CDC 路径重叠 | 全量文件被当作 CDC 重新处理 | S3 端点设置中使用 cdcPath=cdc/ 分离全量和 CDC 目录 |
附录 A:新增表的适配步骤
每张需要同步的源表,重复以下步骤:
| 步骤 | 需要修改的内容 |
|---|---|
| 3.2 — raw 表 | 列名和类型匹配源表 |
| 3.3 — ods 表 | 列名和类型匹配源表,加上 is_deleted |
| 4.1 — 全量 COPY INTO | S3 路径匹配表的目录 |
| 5.1 — Stream | Stream 名称和目标 raw 表 |
| 5.2 — 任务 1(COPY INTO) | S3 路径、raw 表名 |
| 5.3 — 任务 2(MERGE INTO) | 所有列引用、ON 子句和 PARTITION BY 中的主键 |
| 5.4 — 启动 | 任务名称 |
附录 B:DMS 类型映射到 Databend Cloud
| MySQL 类型 | DMS Parquet 类型 | Databend Cloud 类型 |
|---|---|---|
| TINYINT | INT32 | TINYINT |
| SMALLINT | INT32 | SMALLINT |
| INT | INT32 | INT |
| BIGINT | INT64 | BIGINT |
| FLOAT | FLOAT | FLOAT |
| DOUBLE | DOUBLE | DOUBLE |
| DECIMAL(p,s) | FIXED_LEN_BYTE_ARRAY | DECIMAL(p,s) |
| VARCHAR(n) | BYTE_ARRAY (UTF8) | VARCHAR |
| TEXT | BYTE_ARRAY (UTF8) | VARCHAR |
| DATE | INT32 (DATE) | DATE |
| DATETIME | INT64 (TIMESTAMP_MILLIS) | TIMESTAMP |
| TIMESTAMP | INT64 (TIMESTAMP_MILLIS) | TIMESTAMP |
| BOOLEAN / TINYINT(1) | BOOLEAN | BOOLEAN |
| JSON | BYTE_ARRAY (UTF8) | VARIANT |
| BLOB | BYTE_ARRAY | VARCHAR(base64) |
附录 C:各阶段延迟估算
| 阶段 | 典型延迟 |
|---|---|
| 源数据库 → DMS(binlog 读取) | 1-5 秒 |
| DMS → S3(CDC 文件刷盘) | 30-60 秒(由 cdcMaxBatchInterval 控制) |
| S3 → Databend Cloud raw 层(COPY INTO 任务) | 1 分钟(任务调度间隔,可调整) |
| raw → ods(MERGE INTO 任务) | COPY INTO 完成后立即触发 |
| 端到端 | 约 1-2 分钟 |
延迟的主要来源是 DMS 的 CDC 批次间隔。如需降低延迟,可调小 cdcMaxBatchInterval(最小 60 秒)和 cdcMinFileSize。
总结
这套方案通过 AWS DMS + S3 + Databend Cloud 的组合,实现了从 MySQL/Aurora 到数据湖的分钟级实时同步。核心设计思路是:
- 分层存储:raw 层保留完整变更日志,ods 层维护最新状态
- 事件驱动:Stream 机制避免空跑,只在有新数据时触发合并
- 幂等设计:PURGE = TRUE 防止重复摄入,QUALIFY ROW_NUMBER() 保证去重
- 软删除:保留数据完整性,支持审计和回溯
整套管道配置完成后,新增表只需按模板重复固定步骤,运维成本极低。
从 RDS MySQL 到 Databend Cloud 的分钟级 CDC 同步方案
开始使用 Databend Cloud——面向分析、搜索、AI 与 Python Sandbox 的 Agent Ready 数仓,即可开始,获得 200 元代金券。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


