




做过数据管道的人都懂那种感觉:SQL 写完了,还要写调度器;调度器搞定了,还要处理依赖关系;依赖关系理清了,还要配报警。最后发现,一半的时间都花在维护"管道的管道"上,真正处理数据的时间反而少了。
Task Flow 就是为了解决这个问题而生的。
Task Flow 是什么?
Task Flow 是 Databend Cloud 内置的工作流编排功能。你可以把多个 SQL 任务组织成可视化的依赖图,统一调度、实时监控、一键回滚——全部在你的数据已经所在的平台里完成。
不需要额外的服务,不需要维护额外的配置文件。只需要 SQL 和一个可视化编辑器。
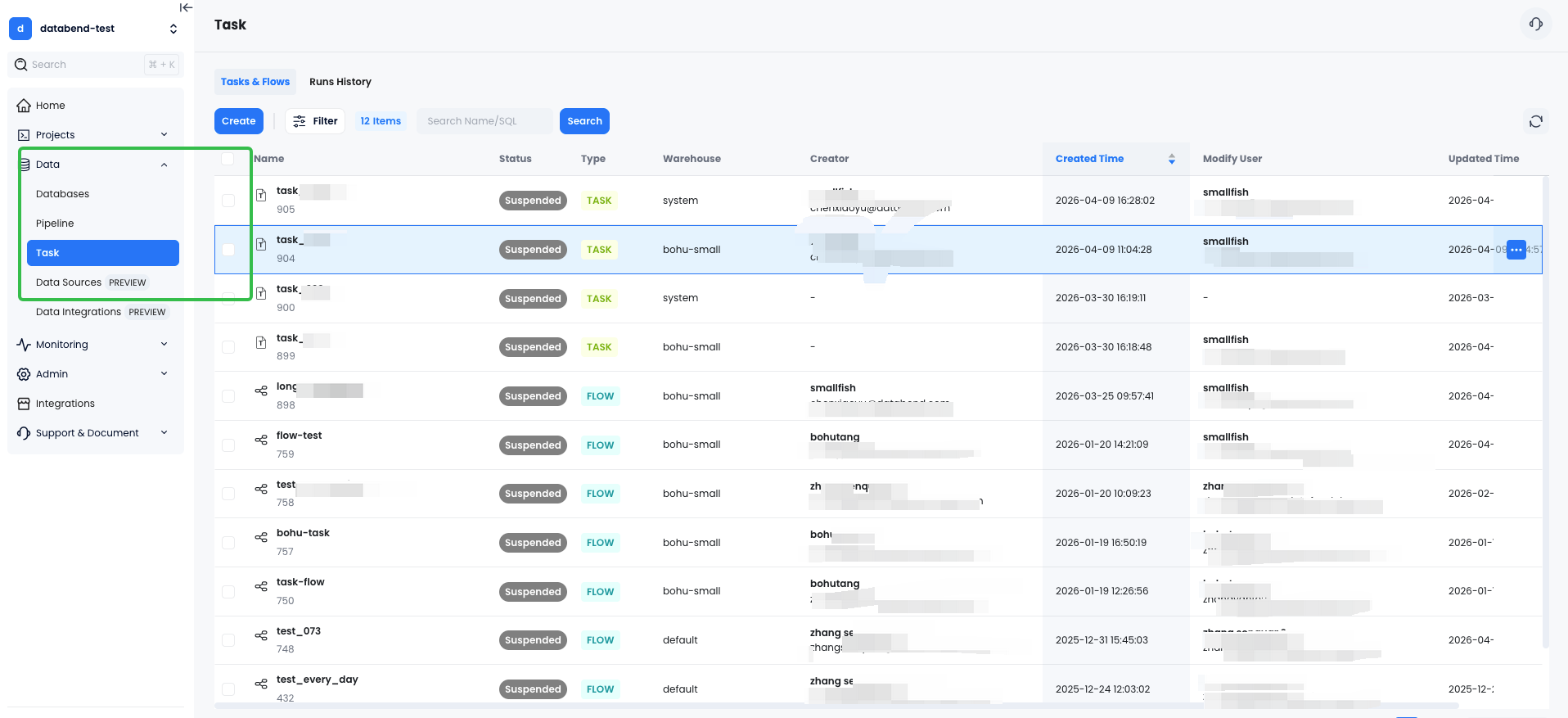
Task Flow 怎么用?
核心逻辑很简单:Task(任务) 是一条带调度配置的 SQL 语句;Flow(流) 是一组有依赖关系的任务集合,绑定一个 Warehouse 来执行。你定义好哪些任务依赖哪些任务,剩下的交给 Databend Cloud。
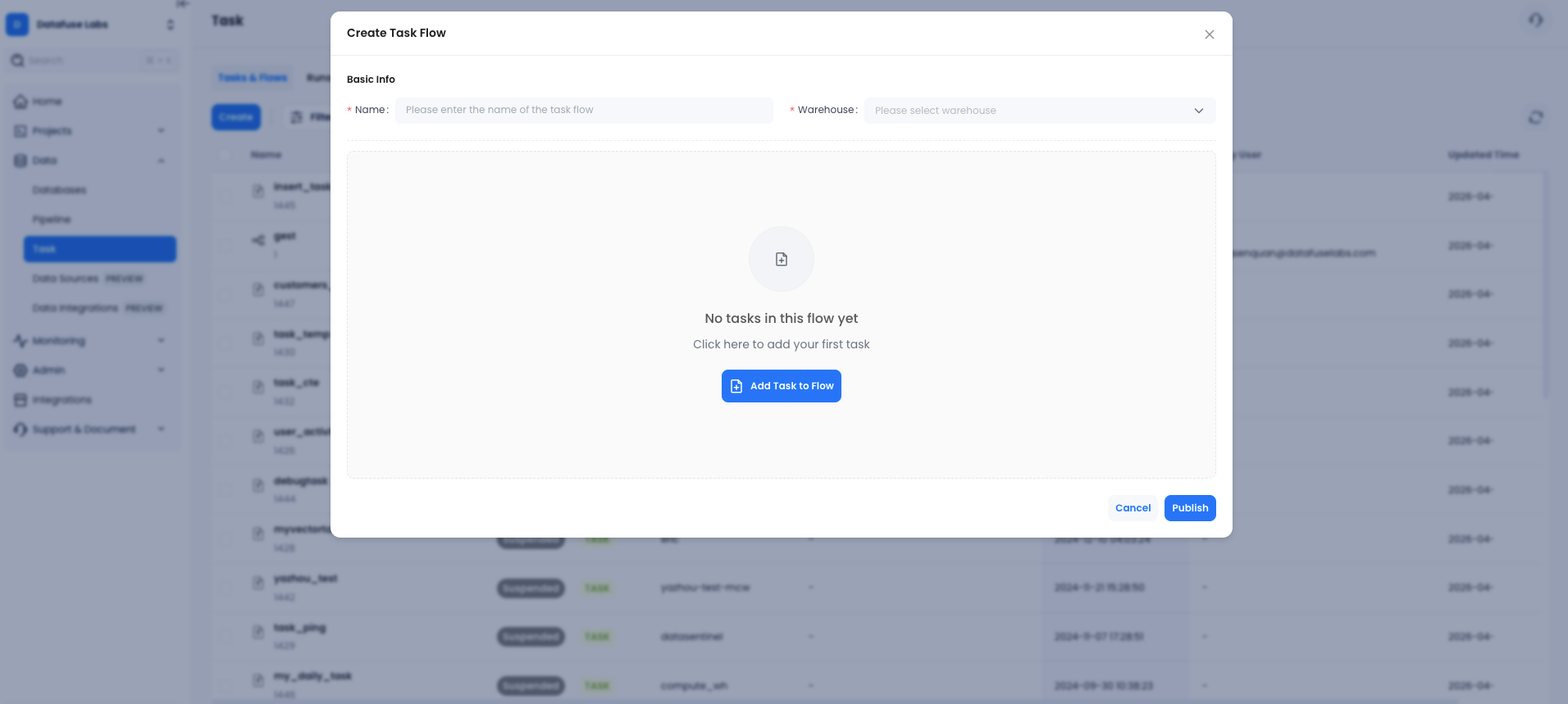
可视化构建管道
创建 Flow 时,你会看到一个图形编辑器。添加任务、连接依赖箭头、点击发布,系统自动推导执行顺序。
每个任务可以独立配置:
- 调度方式(手动触发、按间隔、Cron 表达式,支持时区)
- 上游任务依赖
- Stream 事件触发(只有新的 CDC 数据到来时才执行)
- 失败阈值(连续失败 N 次后自动暂停)
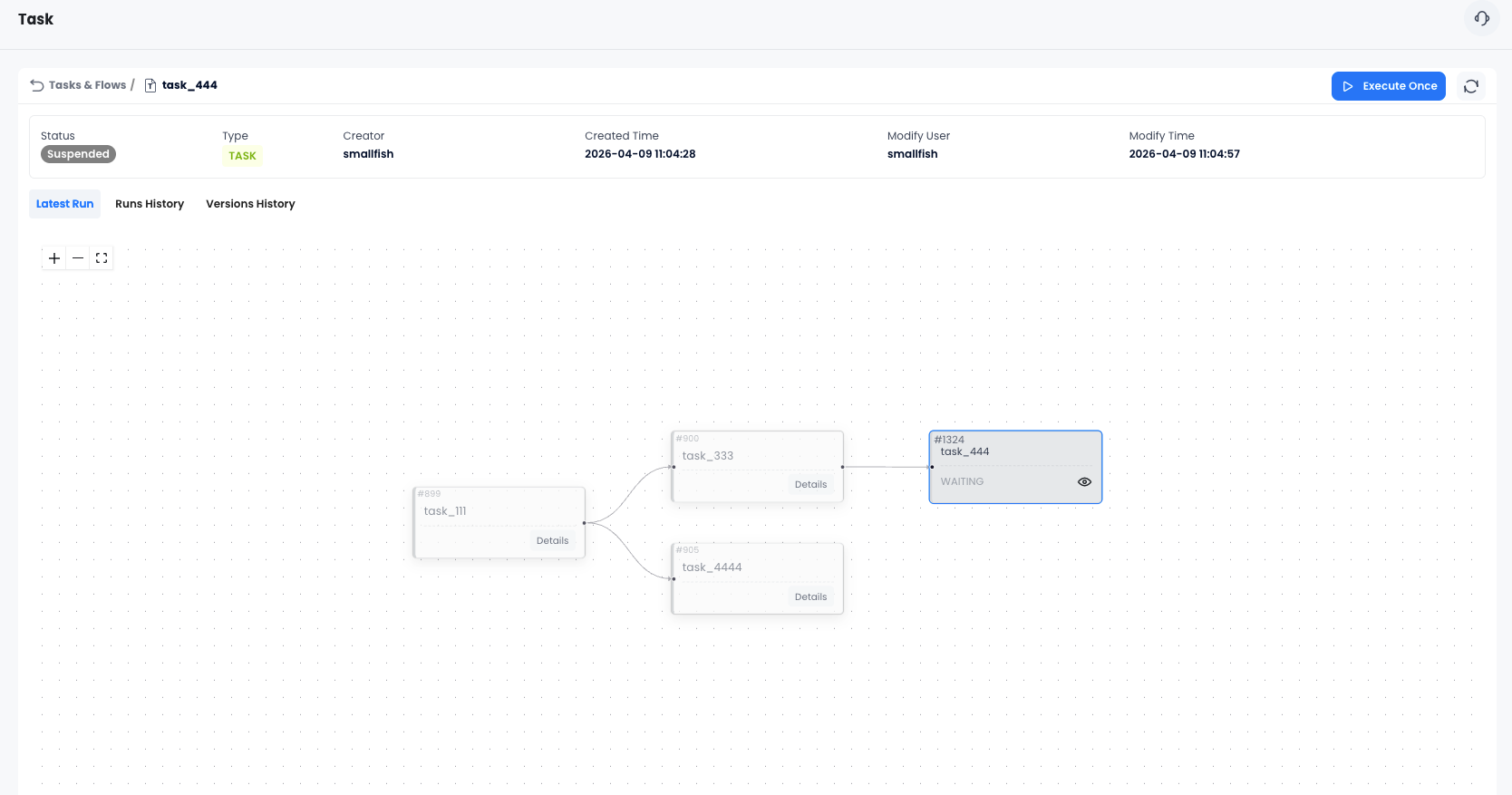
实时看清管道状态
Flow 详情页展示实时 DAG,每个节点都有颜色标注:
- 🟢 绿色 — 执行成功
- 🔴 红色 — 执行失败(悬停查看错误详情)
- 🔵 蓝色 — 等待调度
- ⚡ 浅蓝色 — 执行中
一眼就能看出管道哪一步在跑、哪一步成功了、哪一步出了问题。
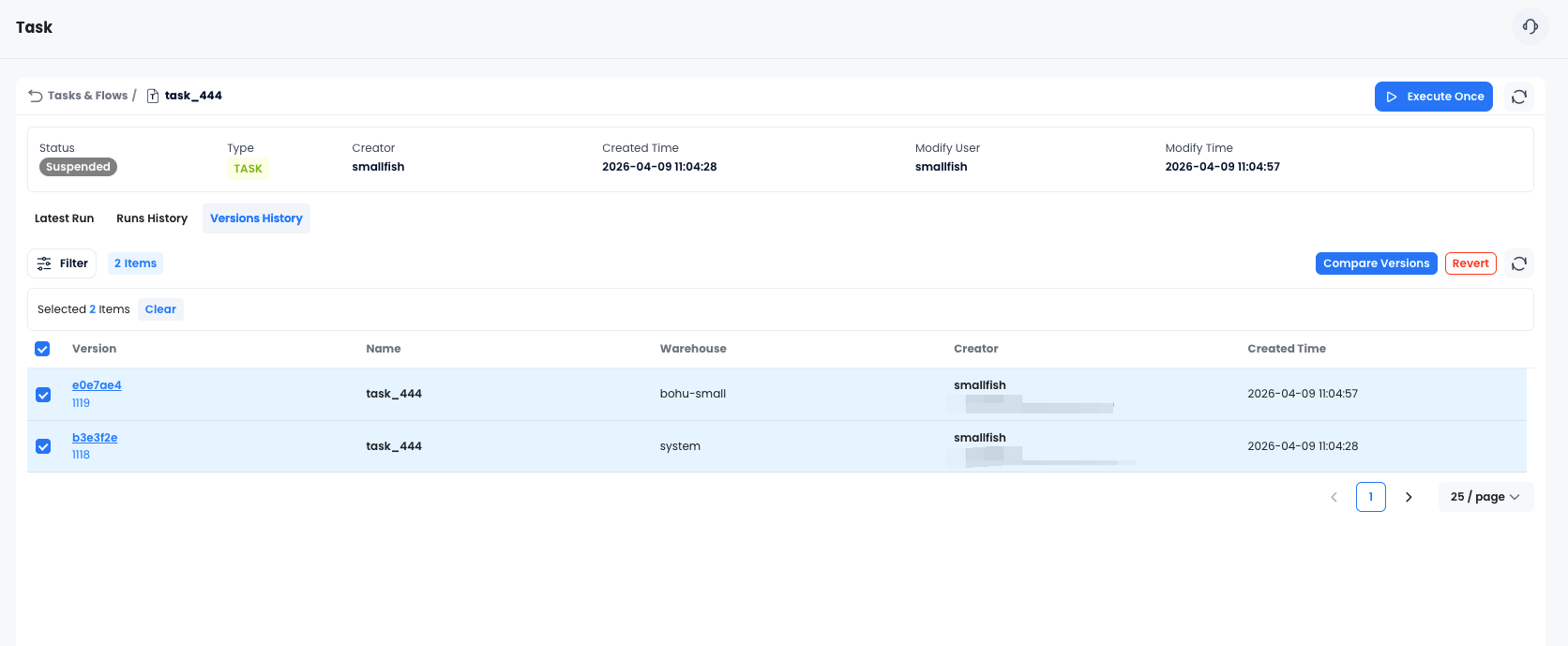
每次发布都有版本快照
每次你修改并发布 Flow,Databend Cloud 都会自动保存一个版本。如果改坏了,你可以:
- 打开版本历史
- 并排对比任意两个版本的 SQL 差异
- 一键回滚到历史版本
这种安全网通常需要单独搭建版本控制流程,在 Task Flow 里是开箱即用的。
典型使用场景
增量数据同步
用 Stream 触发机制构建 CDC 管道。任务监听源表上的 Stream,有新数据时自动触发,执行
MERGE INTO
分层数据转换
将任务串联起来,构建经典的数据分层架构:
原始数据摄入 → Bronze 清洗 → Silver 转换 → Gold 聚合
每一层只在上一层成功后才执行。如果 Bronze 清洗失败,Silver 转换不会触发,下游表的数据始终保持一致。
定时报表刷新
设置一个每天早上 8 点运行的 Flow:刷新物化视图、更新汇总表、触发 BI 工具缓存刷新。一个 Flow,零人工干预。
数据质量检查
在管道末尾加一个校验任务。如果行数异常或空值率突增,任务失败,Flow 自动暂停——在问题数据进入报表之前就拦截住。
和外部编排工具相比,有什么不同?
数据在哪,计算就在哪。 任务直接在 Databend Warehouse 上执行,数据不离开平台,没有网络传输,没有序列化开销。
Stream 触发是一等公民。 大多数编排工具把 CDC 当作附加功能。在 Task Flow 里,任何任务都可以基于 Stream 的数据变化来触发,事件驱动管道和定时管道一样简单。
版本控制是自动的。 不需要额外操作,每次发布就是一次快照。对比、回滚,两步搞定。
权限体系统一。 Task Flow 复用 Databend Cloud 现有的角色权限体系,管理员可以管理所有 Flow,创建者管理自己的 Flow,不需要单独配置权限模型。
立即体验
Task Flow 现已在 Databend Cloud 上线。
- 登录 Databend Cloud
- 进入 数据 → Task & Flows
- 点击 创建,创建你的第一个 Flow
详细的功能说明和配置参考,请查阅官方文档。
数据管道本不该需要一份额外的运维工作来支撑。Task Flow 是我们给出的答案——让编排回归数据本身,让工程师把时间花在真正有价值的地方。
准备好使用 Task Flow了吗?
开始使用 Databend Cloud——面向分析、搜索、AI 与 Python Sandbox 的 Agent Ready 数仓,即可开始,获得 200 元代金券。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


