



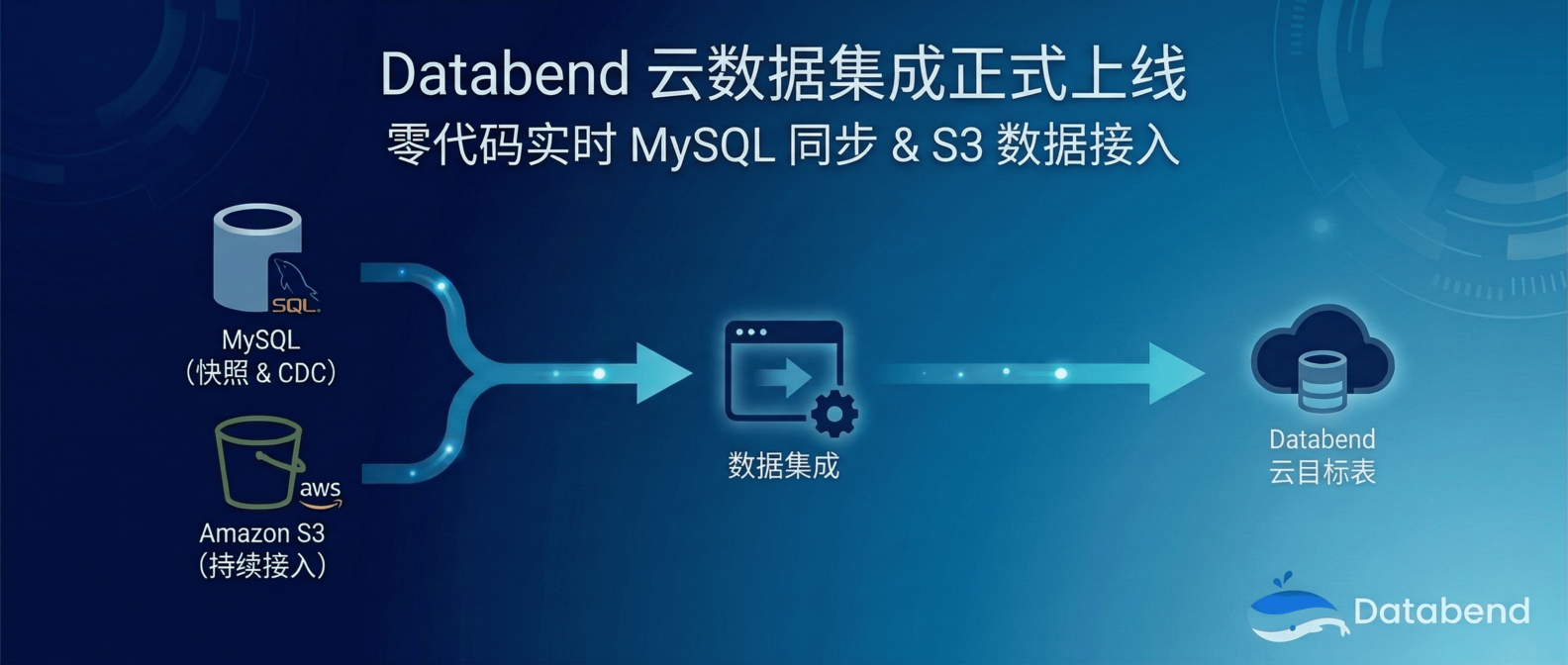
数据集成,一直是数据平台建设中最"重"的一环。搭 Flink、配 Debezium、写 COPY 脚本、调 cron 定时任务……这些工作繁琐、易出错,且维护成本高。
今天,我们正式宣布:Databend Cloud 平台已上线 Data Integration 模块,提供开箱即用的可视化数据集成能力,当前支持 MySQL 和 Amazon S3 两大数据源,覆盖从全量快照到实时 CDC 的完整同步场景——全程零代码,几分钟即可完成配置。
为什么需要 Data Integration?
在传统的数据入仓流程中,用户通常需要:
- 自行部署和维护 CDC 工具(如 Debezium、Flink CDC、Canal 等)
- 编写和调试数据加载脚本(COPY INTO、Stage 配置等)
- 处理 Schema 映射、类型转换、错误重试等细节
- 搭建监控体系来追踪同步状态
这些环节不仅消耗大量工程资源,还容易在生产环境中引发数据不一致的问题。
Databend Cloud Data Integration 的目标很明确:把这些复杂度收敛到平台内部,让用户只需关注"从哪来、到哪去"。
核心架构:Data Source + Integration Task
Data Integration 采用两层抽象设计:
- Data Source(数据源):存储外部系统的连接凭证和配置信息,支持复用。当前支持 MySQL 和 AWS S3 两种类型。
- Integration Task(集成任务):定义数据从源到目标表的流转逻辑,包括同步模式、目标表映射、运行参数等。
这种解耦设计意味着,一个数据源可以被多个任务共享,管理更加灵活。
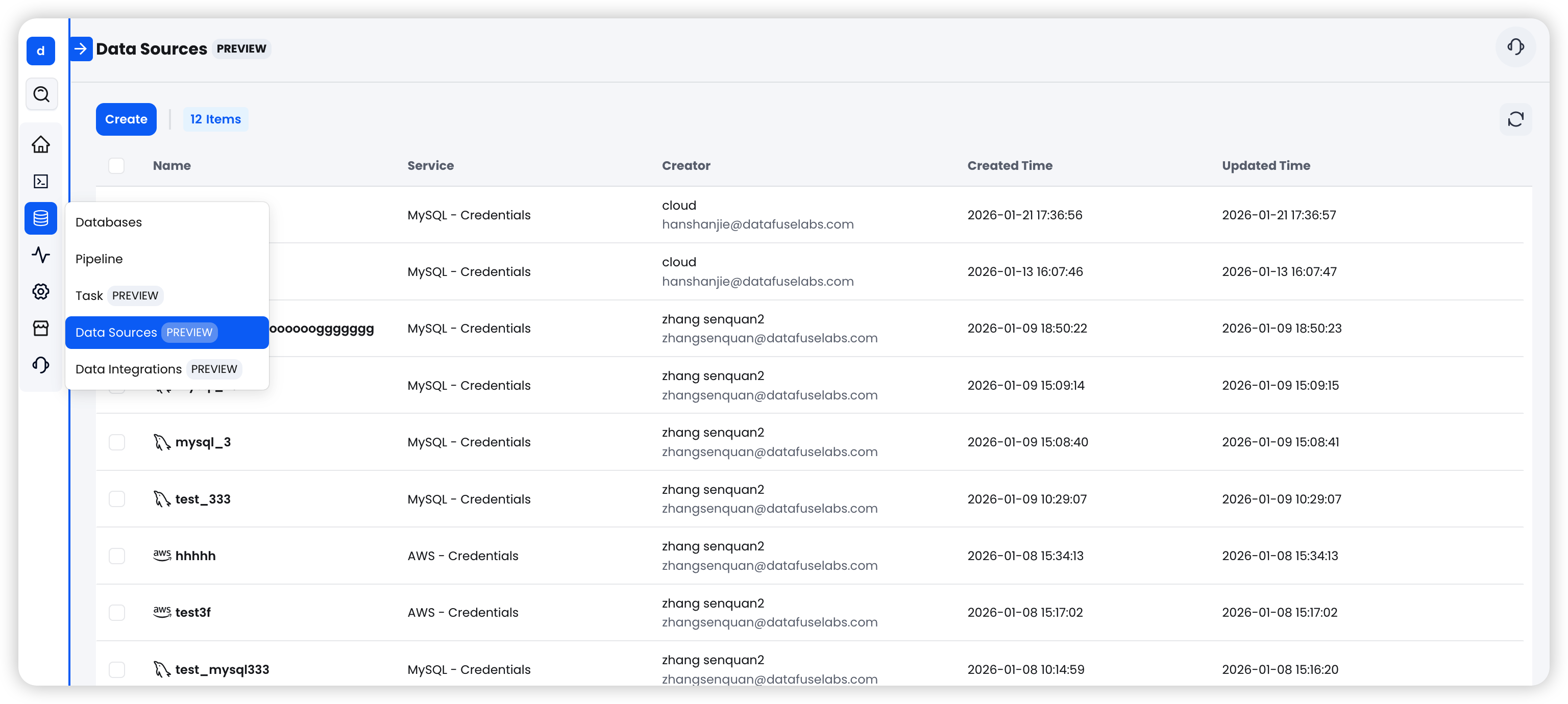
MySQL 集成:从快照到实时 CDC,一站搞定
MySQL 是最常见的业务数据库之一。Data Integration 提供了三种同步模式,覆盖不同场景需求:
三种同步模式
| 模式 | 适用场景 | 行为 |
|---|---|---|
| Snapshot(快照) | 初始数据迁移、定期全量刷新 | 一次性全量读取源表数据,完成后自动停止 |
| CDC Only | 实时数据同步、事件驱动管道 | 持续监听 MySQL Binlog,捕获 INSERT/UPDATE/DELETE 变更 |
| Snapshot + CDC | 大多数生产场景(推荐) | 先执行全量快照,再无缝切换到 CDC 持续同步 |
对于大多数用户,我们推荐使用 Snapshot + CDC 模式——它确保了完整的初始数据加载,并在此基础上实现持续的实时同步,是最省心的选择。
创建流程:三步完成
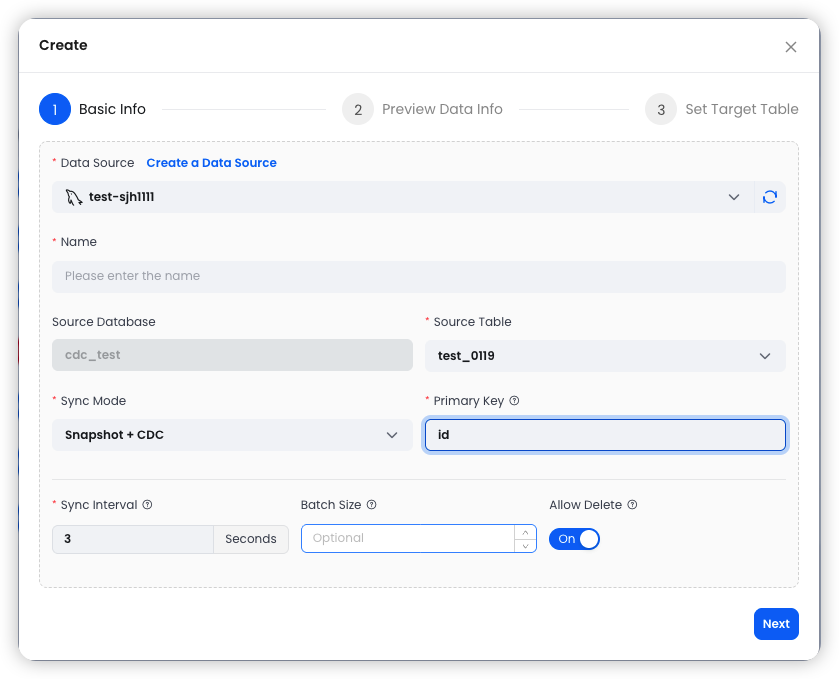
第一步:配置基本信息
选择已创建的 MySQL 数据源,指定源表和同步模式,配置 Conflict Key(冲突键,通常为主键)、Merge Interval(合并间隔)等参数。
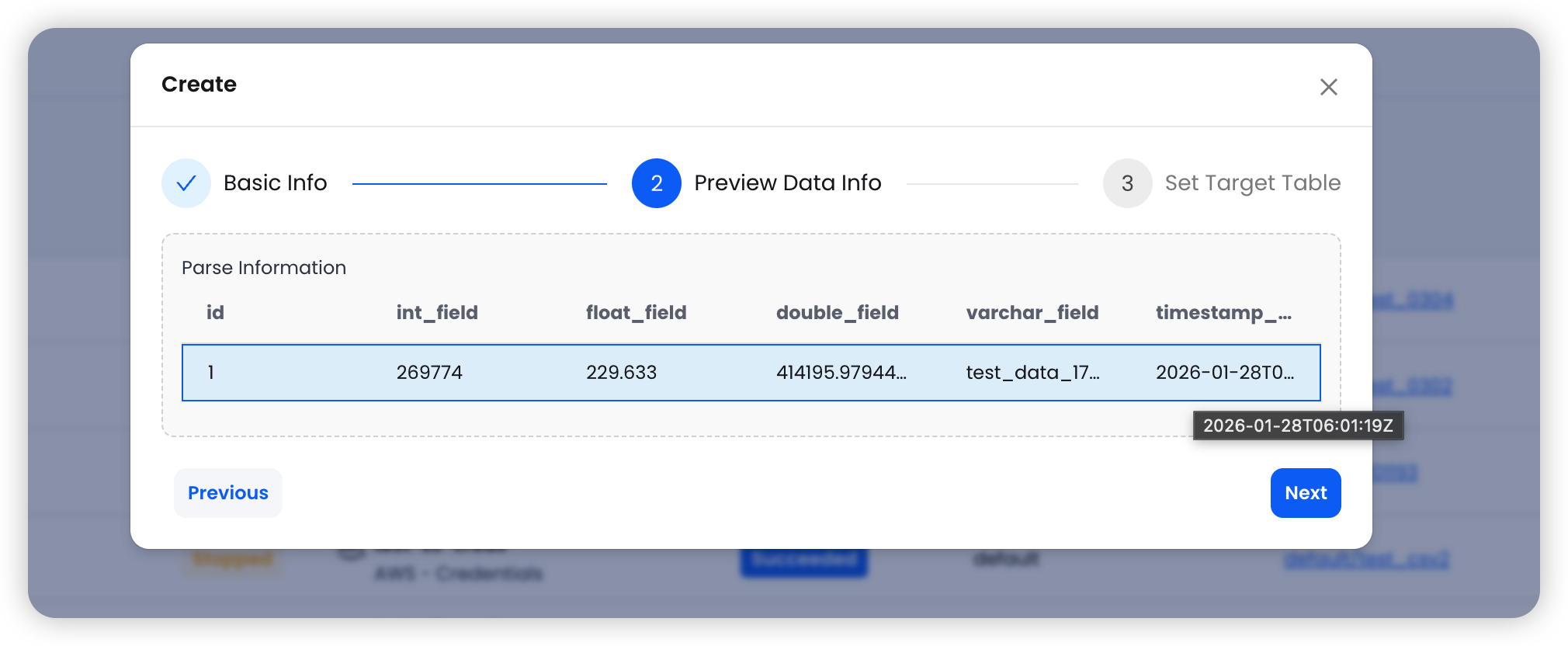
第二步:预览数据
系统自动从源表拉取样本数据,展示列名和数据类型,确认无误后继续。
第三步:设置目标表
选择目标 Warehouse、数据库和表名,系统自动完成 Schema 映射。
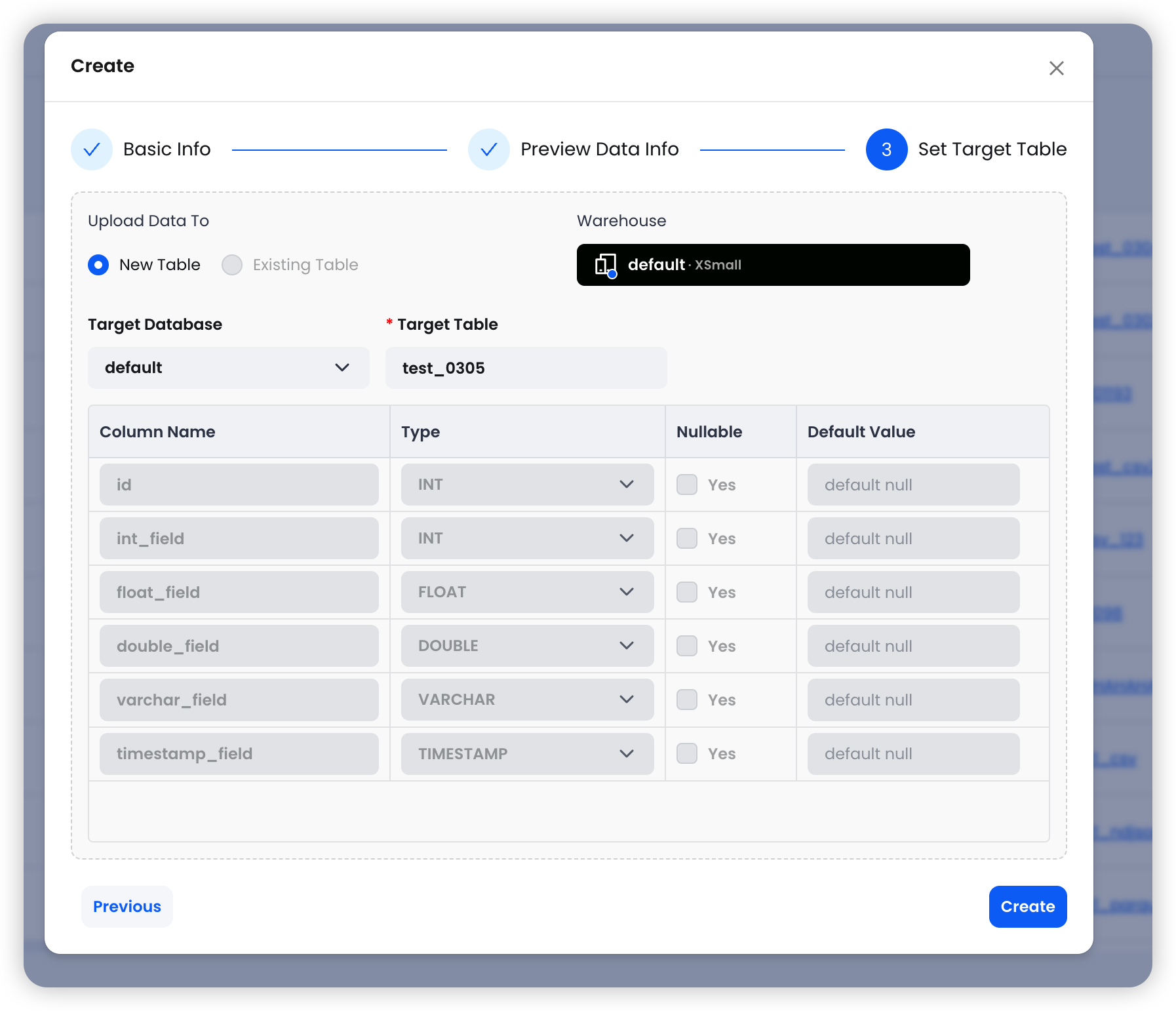
点击 Create 即完成任务创建。
进阶能力
- WHERE 条件过滤:Snapshot 模式下支持 SQL WHERE 子句,按条件加载部分数据(如 )created_at > '2024-01-01'
- 定时归档(Archive Schedule):支持 Cron 表达式配置周期性快照,按天/周/月自动执行
- Allow Delete 控制:可选择是否将 MySQL 端的 DELETE 操作同步到 Databend,关闭后可保留完整历史记录,适合审计场景
- 断点续传:CDC 任务停止时自动保存 Binlog 位点,重启后从断点继续,不丢数据
Amazon S3 集成:文件入仓从未如此简单
对象存储是数据湖架构的基石。Data Integration 的 S3 集成让你无需编写任何 COPY INTO 语句,即可将 S3 中的文件持续导入 Databend。
支持的文件格式
| 格式 | 特点 |
|---|---|
| CSV | 支持自定义分隔符、表头检测,最通用的数据交换格式 |
| Parquet | 列式存储,分析场景下性能优异 |
| NDJSON | 每行一个 JSON 对象,适合日志和事件数据 |
通配符匹配
文件路径支持通配符模式,灵活匹配多个文件:
s3://mybucket/data/2025-*.csv # 匹配所有 2025- 开头的 CSV 文件
s3://mybucket/logs/*.parquet # 匹配 logs 目录下所有 Parquet 文件
s3://mybucket/events/data.ndjson # 指定单个文件
创建流程同样三步走
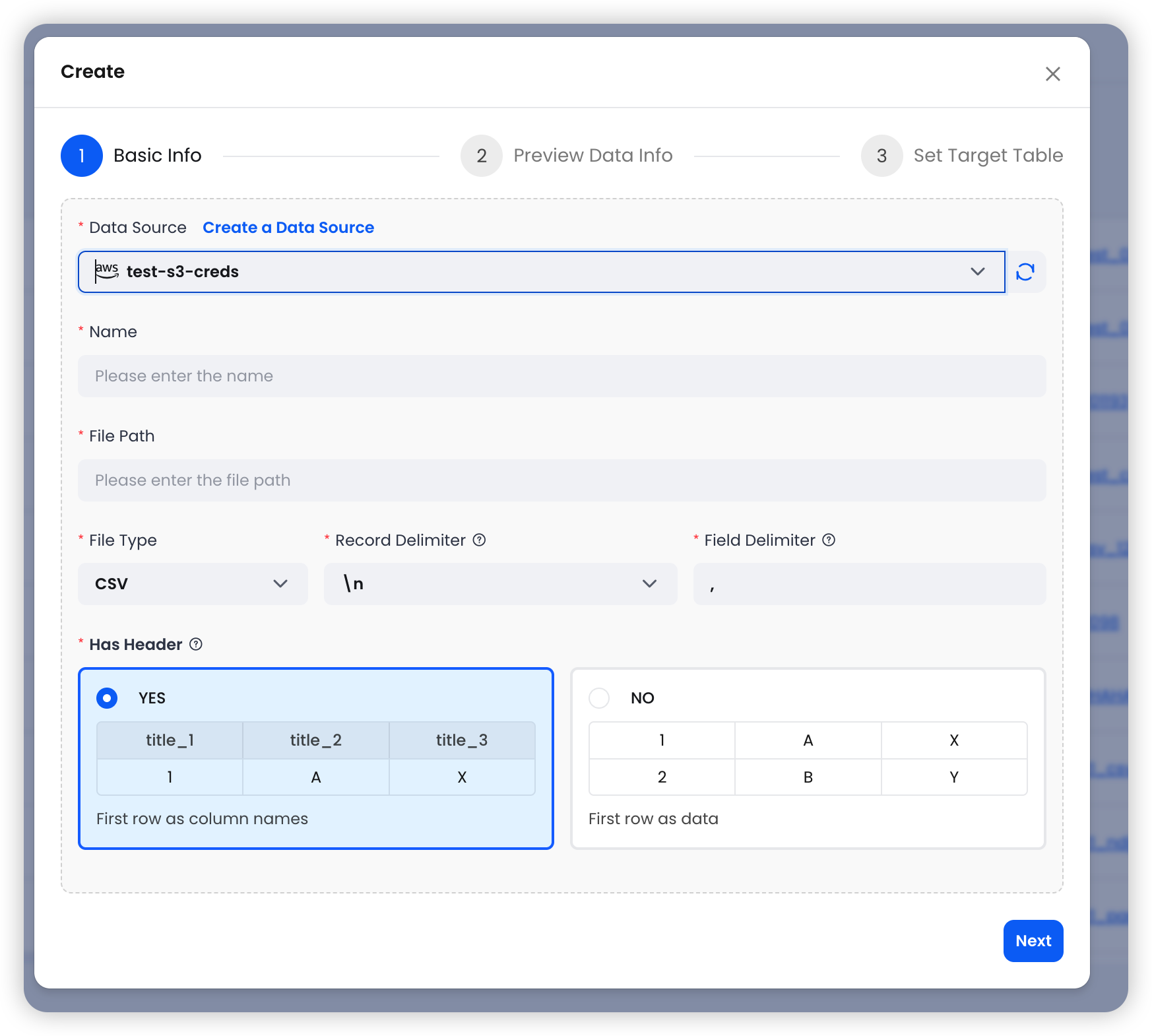
第一步:配置基本信息 — 选择 S3 数据源,填写文件路径和格式。
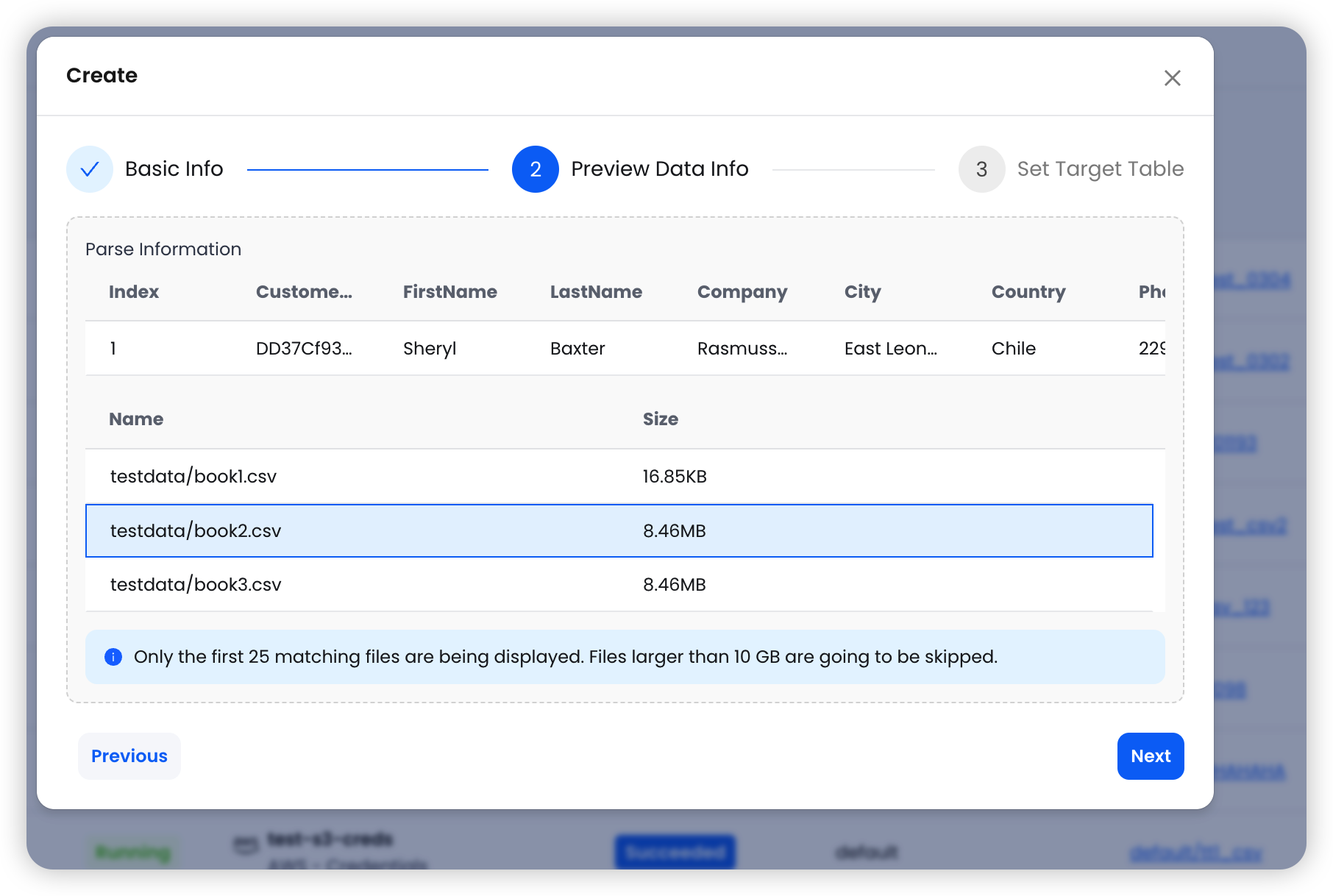
第二步:预览数据 — 系统读取首个匹配文件,展示样本数据和匹配文件列表。
第三步:设置目标表 — 选择目标 Warehouse 和表,配置导入选项。
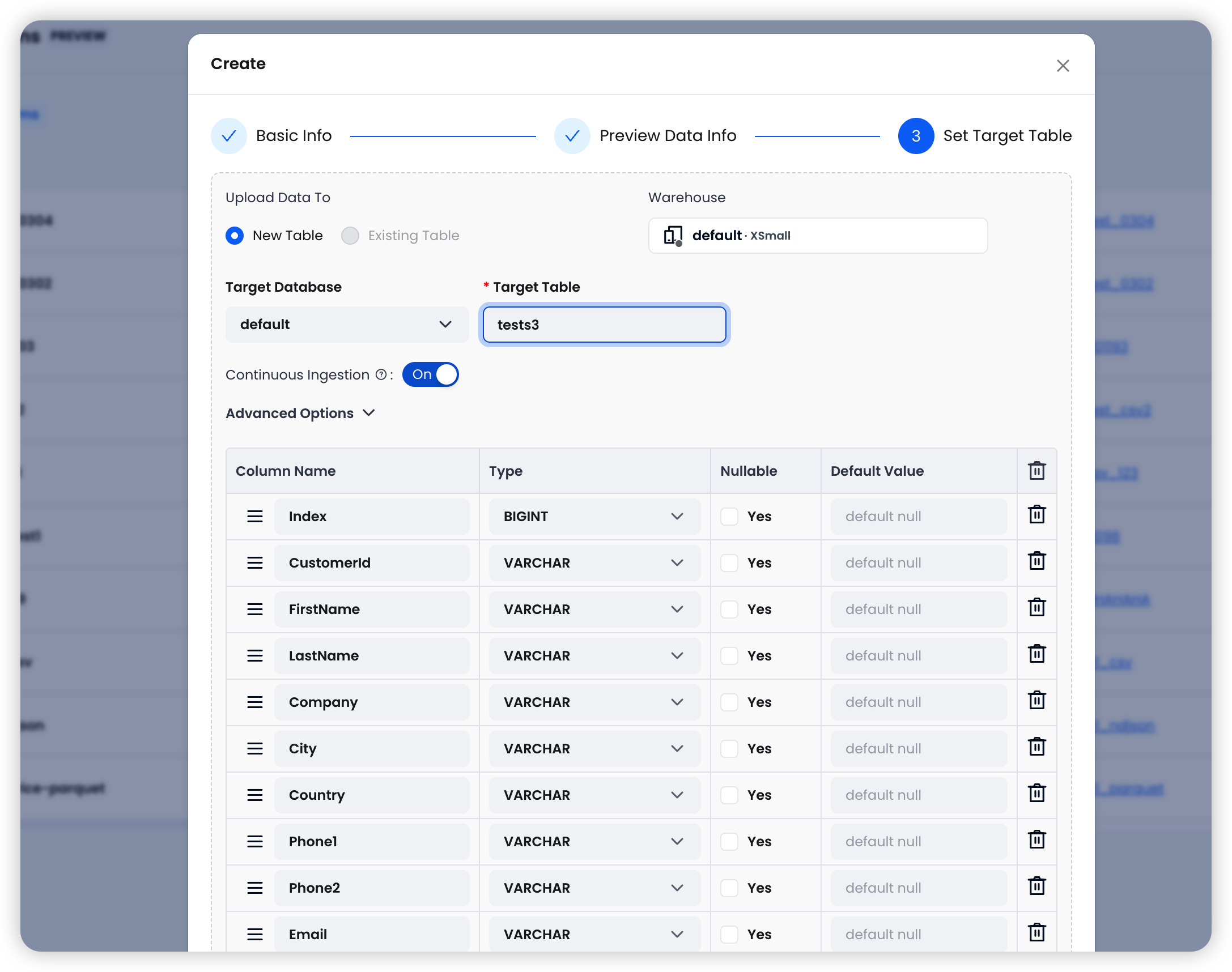
四大导入选项,精细控制数据流
| 选项 | 默认值 | 说明 |
|---|---|---|
| Continuous Ingestion(持续导入) | 开启 | 每 30 秒自动轮询 S3 路径,发现新文件即自动导入 |
| Error Handling(错误处理) | Abort | Abort:遇错即停;Continue:跳过错误行继续导入 |
| Clean Up Original Files(清理源文件) | 关闭 | 导入成功后自动删除 S3 源文件,节省存储成本 |
| Allow Duplicate Imports(允许重复导入) | 关闭 | 开启后允许重新导入已处理过的文件,适用于 Schema 变更后的数据重载 |
持续导入模式特别适合上游系统持续写入 S3 的数据管道场景——配置一次,数据自动流入 Databend,无需额外的调度系统。
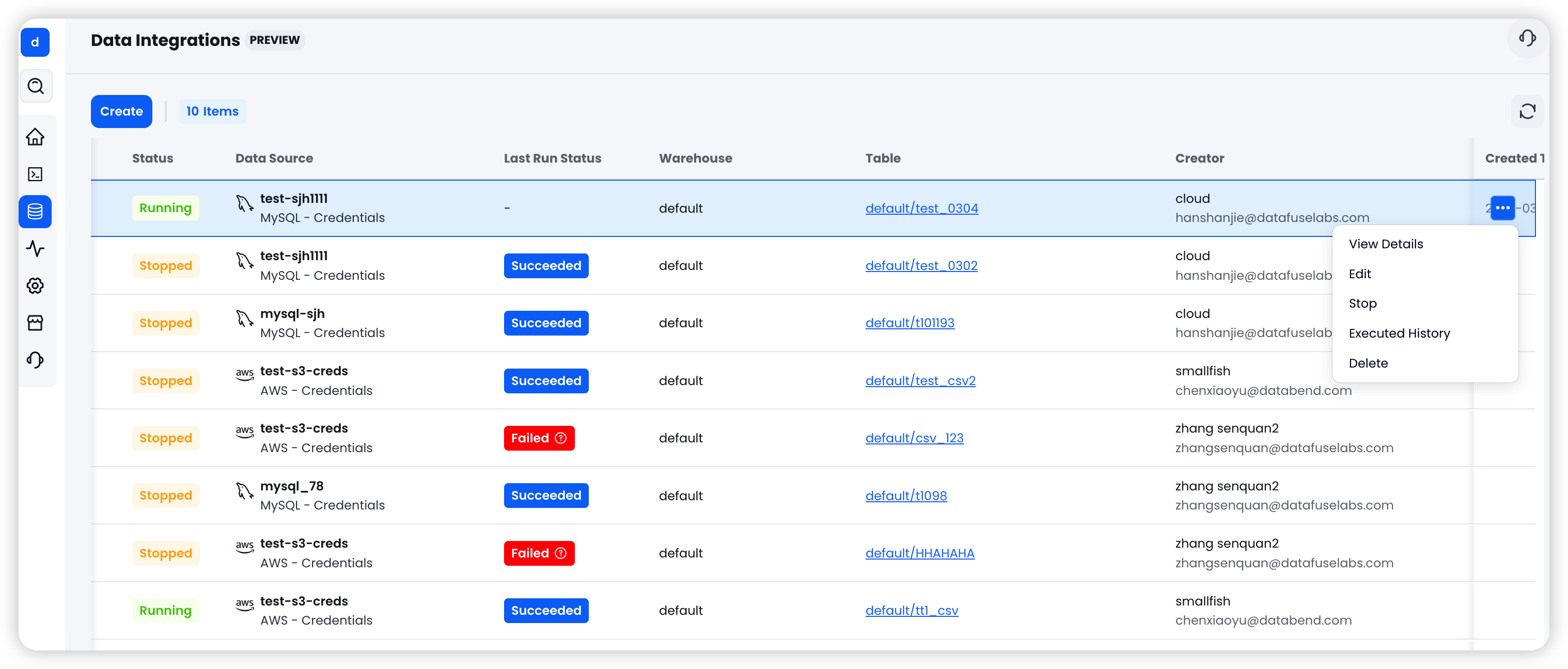
统一的任务管理与监控
所有集成任务在同一界面统一管理,支持:
- 启动 / 停止:任务创建后默认处于 Stopped 状态,一键启动即可开始同步
- 状态追踪:Running / Stopped / Failed 三种状态一目了然
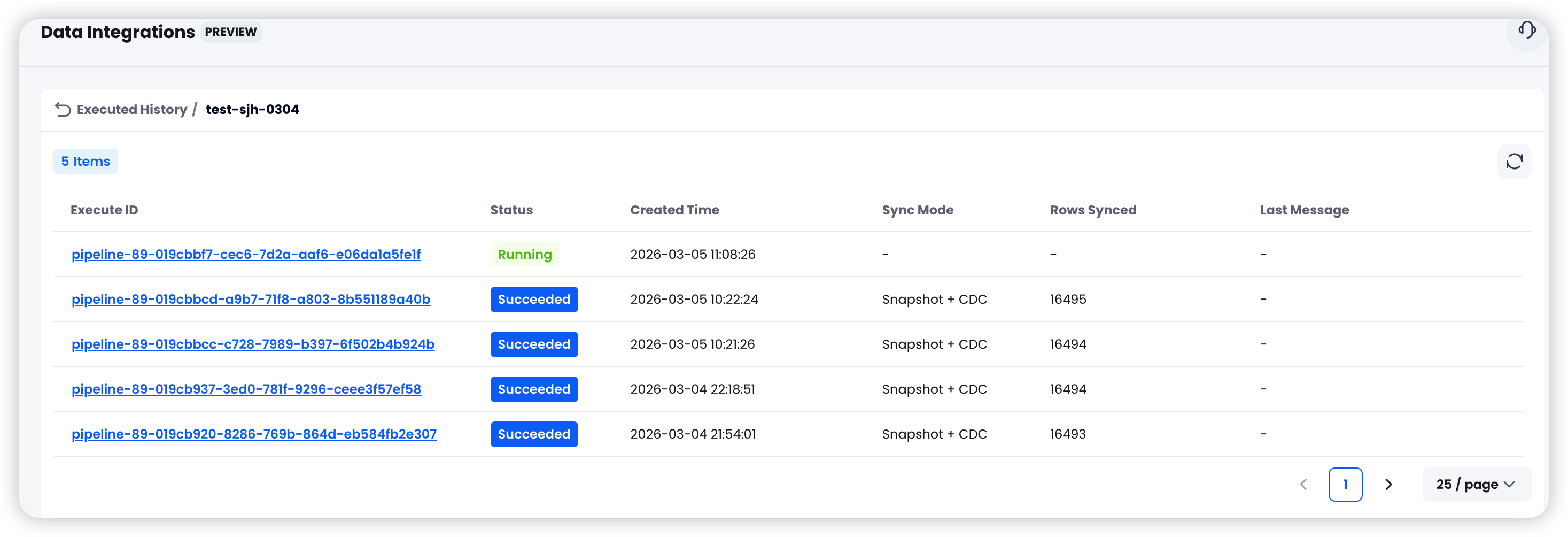
- 运行历史:查看每次执行的起止时间、同步行数、错误详情
典型应用场景
场景一:MySQL 业务库实时同步到 Databend 做分析
电商平台的订单表、用户表存储在 MySQL 中,业务团队需要在 Databend 上做实时报表和 BI 分析。使用 Snapshot + CDC 模式,先全量同步历史数据,再实时捕获增量变更,分析侧始终保持与业务库的数据一致性。
场景二:S3 日志数据持续入仓
应用日志以 NDJSON 格式持续写入 S3。开启 Continuous Ingestion,Databend Cloud 每 30 秒自动扫描新文件并导入,配合 Clean Up Original Files 选项自动清理已处理文件,构建一条全自动的日志分析管道。
场景三:定期归档 MySQL 数据
财务系统需要按月归档交易数据。使用 Snapshot 模式配合 Archive Schedule,设置 Cron 表达式按月自动执行快照,指定时间列进行分区,实现无人值守的定期数据归档。
快速上手
- 登录 Databend Cloud
- 进入 Data > Data Sources,创建你的第一个数据源
- 进入 Data > Data Integration,创建集成任务
- 点击 Start,开始同步
整个过程不需要写一行代码,不需要部署任何外部组件。
写在最后
Data Integration 是 Databend Cloud 在数据集成方向迈出的重要一步。我们希望通过平台化的能力,让数据工程师从繁琐的 ETL 管道搭建中解放出来,把精力聚焦在更有价值的数据分析和业务洞察上。
当前已支持 MySQL 和 Amazon S3 两大数据源,更多数据源(如 PostgreSQL、Kafka 等)正在规划中。如果你有特定的数据源需求,欢迎通过社区反馈给我们。
立即登录 Databend Cloud,体验全新的 Data Integration 功能。
视频导览
了解更多:
使用 Databend Cloud 上 Data Integration 同步 MySQL 数据
开始使用 Databend Cloud——面向分析、搜索、AI 与 Python Sandbox 的 Agent Ready 数仓,即可开始,获得 200 元代金券。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


