




游戏行业实际上是一个离钱特别近的行业。很多时候上线一个游戏,要求在半年内回本,如果半年内不能回本,这个游戏项目可能就慢慢进入冷宫了。游戏行业的这种节奏,反映到数据生产角度,每秒钟产生几十万条事件,一天产生几十 TB 数据属于常态。
游戏业务需求非常多,如运营层、玩法层、经济层等。比如四五个人组成的一个流量小组,要投放 100 万流量,这个时间段内能否赚回这 100 万?这几天如何分析数据?对于这样的数据分析需求,如果还用传统的方法做成看板展示,基本上不太现实。这种时候,团队通常会直接使用 SQL 查询,再把数据导出到 Excel 表里。一个个灵活的需求都是这样去实现分析的,需求量极大。

此外,游戏行业的数据工程师经常会面对堆积如山的需求量。很多在海外工作的朋友头衔叫“Data Engineer”(数据工程师)。最初很疑惑,他们做的是什么神奇工作?但交流后才发现,他们大部分时间都在写 SQL,做临时统计和需求导出,基本上每天要做很多个 Excel,可能有 30 多个甚至几百个的任务。
在如此庞大的需求下,游戏行业的数据治理非常复杂。数据来源方面,经常分成网页游戏、客户端游戏,而客户端游戏中又细分出不同的手机平台,比如 iPhone 和安卓,而安卓又分成不同品牌。这些不同品牌、不同渠道来的用户情况如何?用户体验怎么样?甚至具体到不同尺寸屏幕上的游戏效果如何?再比如说游戏的码率问题,通常看到的是每秒 60 帧的数据,而很多游戏会把这 60 帧里的每一帧都存下来,甚至每次交互的时延数据也都保存下来,以便做后续的优化。另外,游戏中还会有“爽感刺激”设计,比如玩家在游戏过程中砍一个怪,系统会给予什么奖励?玩家完成某个任务后,能否实时推送相应奖励?或者一局对战只有 15 分钟,结束之后如何快速匹配下一局对手,让玩家的游戏体验更好,留存更高?如何做到实时处理?一局结束之后如何快速展示玩家的荣耀时刻和游戏战绩?这些都是对实时流计算能力的巨大挑战。
曾经接触过一个团队,游戏排名在 iPhone 榜单上进入了 TOP 10,当时他们的大数据团队有 50 多人,但仍然接不完所有业务需求,一个需求通常要排两到三天才能解决。这种情况在传统的大数据团队里非常常见,成为一种标准的业务处理模式。所以,面对传统大数据方案的快速业务迭代,很多公司会陷入更狼狈的境地。在实际场景中,可以看到大量的 Flink 任务满天飞,各种任务迟到和排队现象十分严重。
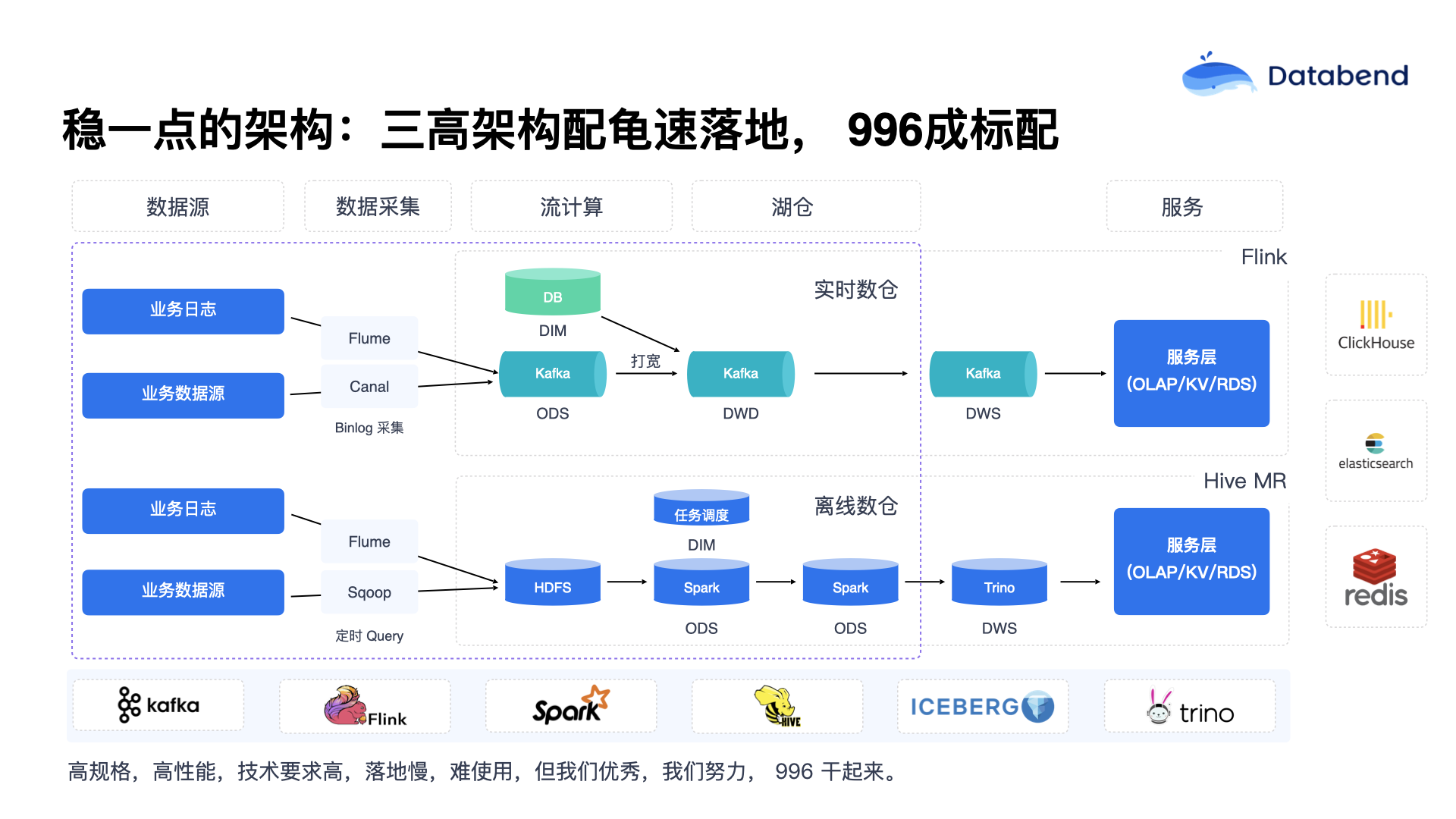
一些游戏公司早期架构都是类似情况。虽然看上去只有几个组件,但实际情况远比想象的复杂得多。比如一个 NameNode 或者目录服务背后,至少还有一个 MySQL 数据库,服务之间的可用性发现至少要依靠 ZooKeeper。这些堆积起来的组件,最终发现远比想象中多。如果环境搭建没有做到很好的自动化,就会非常难搞。游戏行业不管是哪个环节,如果没做好自动化管理,基本上都是 996 工作模式。甚至更严重的情况是“996 是起步,严重的可能高达 8 个月的高强度工作”。这里面的组件太多,出问题后的排查也特别困难。
此外,平台稳定性也是很大的挑战。数据搬运工作往往占据了 80% 的工作量。数据工程师常常自嘲是“数据搬运工”,每天最擅长的事情就是把数据从 A 搬到 B,从 B 搬到 C,进行聚合计算和数据钻取分析。平台的计算资源瓶颈明显,平台的任务队列化非常严重。MySQL 数据库讲究的是高并发,强调一次可以处理几万个并发请求,而传统大数据团队却常常忍受任务一个个慢慢跑,实际处理起来非常麻烦。
此外,游戏平台还有一个最大问题是安全方面的挑战。平台引入了大量堆积的组件,虽然这些组件当时很好用,但一旦出安全问题,就完全不知道是哪一个组件出了故障。最后数据环节一旦掉链子,整个数据链路都会被拖累。因此在大数据平台中,网络隔离是特别需要关注的环节。还有一种严重挑战是一旦 IDC 出现故障,往往需要迁往外机房,搞同城互备,这也是一件麻烦的事。
如何给游戏行业数据分析带来 10 倍收益提升?
Databend 目前所做的工作是从过去的数据仅能“存起来”,逐渐转变为切入业务场景,直接帮助业务提升效率。
海量数据:秒级摄入及可见
首先,Databend 实现了海量数据秒级摄入能力,这与传统大数据行业有明显区别。传统大数据更多讲究的是批处理(Batch),一般来说,批处理的间隔最少也要 5 分钟或 30 分钟一个批次。Databend 所强调的是数据的秒级摄入,并实现逐级实时处理,做到数据的实时可见。
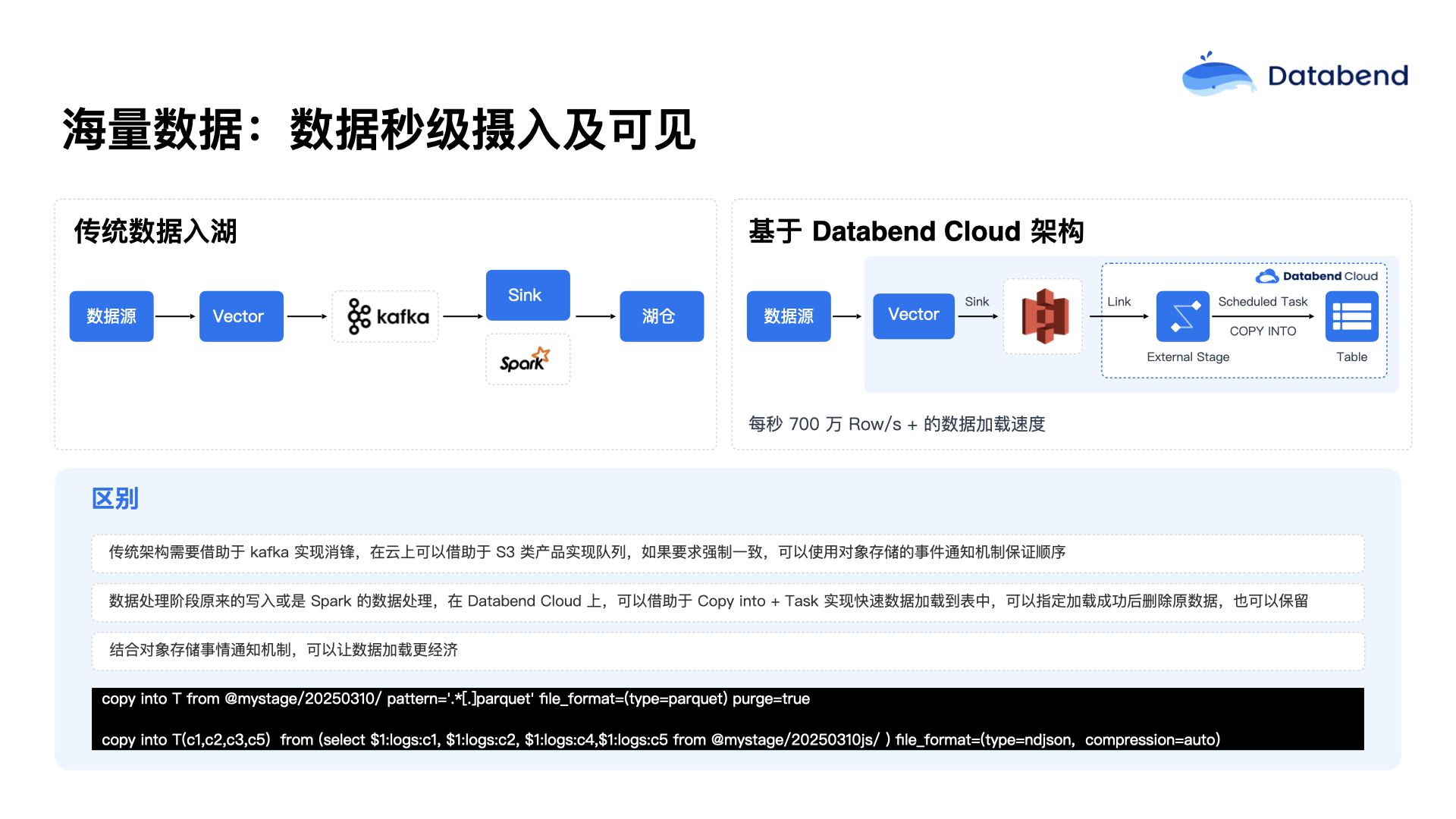
上图左侧是传统场景下的数据写入流程,通常都是从数据源到 vector,到 Kafka,到 Spark,再到湖仓,大致都是通过这样的链路去完成数据的写入过程。这个链路看起来每个环节非常清晰,但最大的一个问题在于:云端每增加一个组件都需要付费。多增加一个组件,就意味着多一份费用,也意味着多一份维护工作。
能不能将链路进一步简化?能否做到数据源直接写入对象存储?对象存储能否代替 Kafka 的作用?例如,可以让多个、甚至上百个应用直接将数据写入到对象存储中。当数据写入对象存储后,Databend 内部有一个概念叫 External Stage,可以根据对象存储的具体位置进行关联,并且直接调用 Databend 的
COPY INTO
目前测试下来,在一个标准的云服务器上,平均能实现每秒大约 700 万条数据的加载速度。这个速度通常受限于对象存储的带宽,基本可以压满带宽或单节点的性能进行加载。在加载的过程中,Databend 也支持进行数据的转换(Transform)。但 Databend 坚持能不做 Transform 尽量不做,数据尽量以 ODS 层的原始状态加载进来,然后再对原始数据进行处理,这样也更容易与原始端的数据对齐。
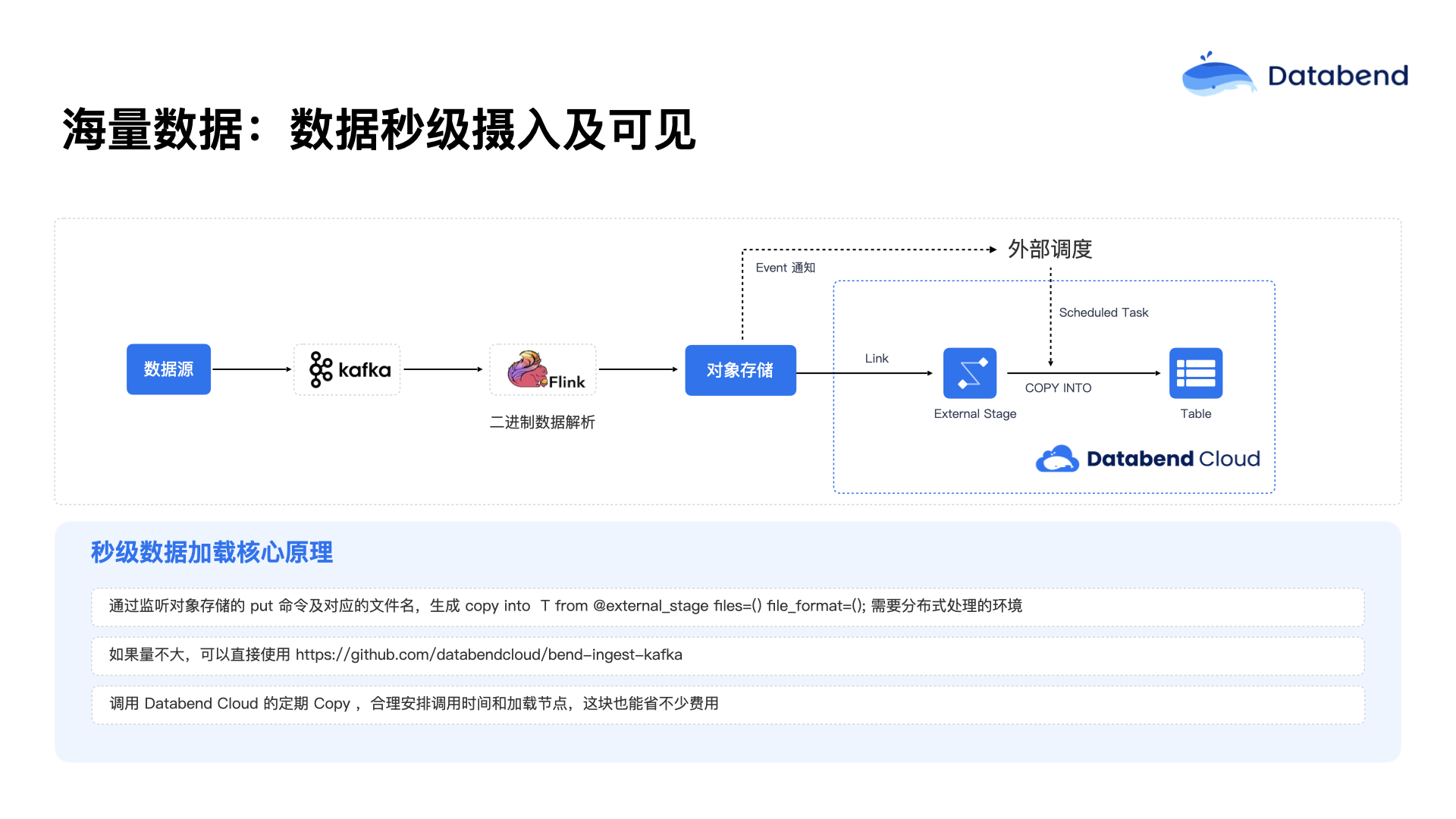
此外,Databend 也可以利用对象存储本身提供的事件(Event)通知机制。用户可以订阅对象存储的事件通知,当有
PUT
在实际使用中,也有一些客户依然会保留 Flink 和 Kafka 这样的组件。在与一些车企或者物联网行业合作时发现,这些行业的数据很多都是二进制的格式。由于 Databend 目前无法直接处理二进制数据,因此需要使用 Flink 先将这些二进制数据转化为 JSON 或其他结构化格式,再由 Databend 来处理。目前 Databend 能够直接处理的格式包括 CSV、TSV、NDJSON、JSON、Parquet、ORC、Arrow 等常见格式,以及对应的压缩格式也。基本上,Databend 能够替代 Spark 的绝大部分数据处理工作。
因此,在理想情况下,用户可以将 Kafka 和 Spark 两个环节完全去掉,直接使用对象存储对齐数据即可。当然,如果你的数据格式不太规范,或者有一些特殊的需求,建议保留原有的预处理过程,然后再进行加载。
表级增量捕获,实现增量计算
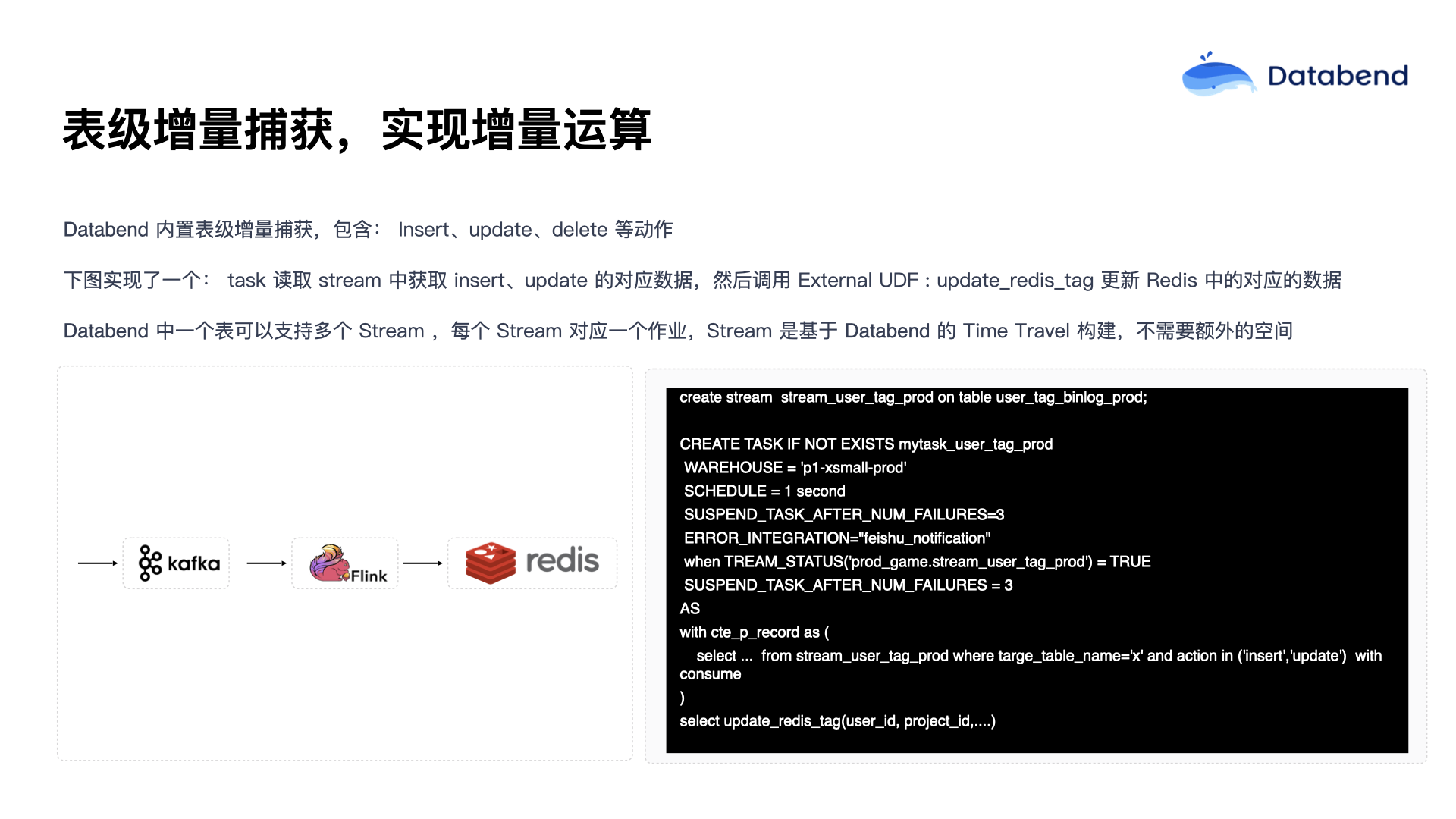
前面提到游戏行业的实时数据看板场景。假设用户打完一局游戏后,需要实时看到整体的游戏数据展示。传统的实现流程一般是数据先接入到大数据平台,再通过 Flink 处理,处理完毕后再写入 Redis 或者 MySQL 中。这样,游戏用户在游戏结束后,可以直接从数据库里读到相关的数据。
而在 Databend 中,提供了一种叫做表级增量捕获(Table-level CDC)的功能,即可以记录某张表中的
INSERT
UPDATE
DELETE
很多海外用户会通过这种方式把数据写入 MySQL 或其他比较大的湖仓产品,或者直接提供外部服务的 Redis 等产品。这种方案基本上可以视为一个标准方案,即逐步使用 Databend 提供的增量捕获能力替代原有的 Kafka 组件,同时通过外部的 UDF 替代原有的 Flink 处理。
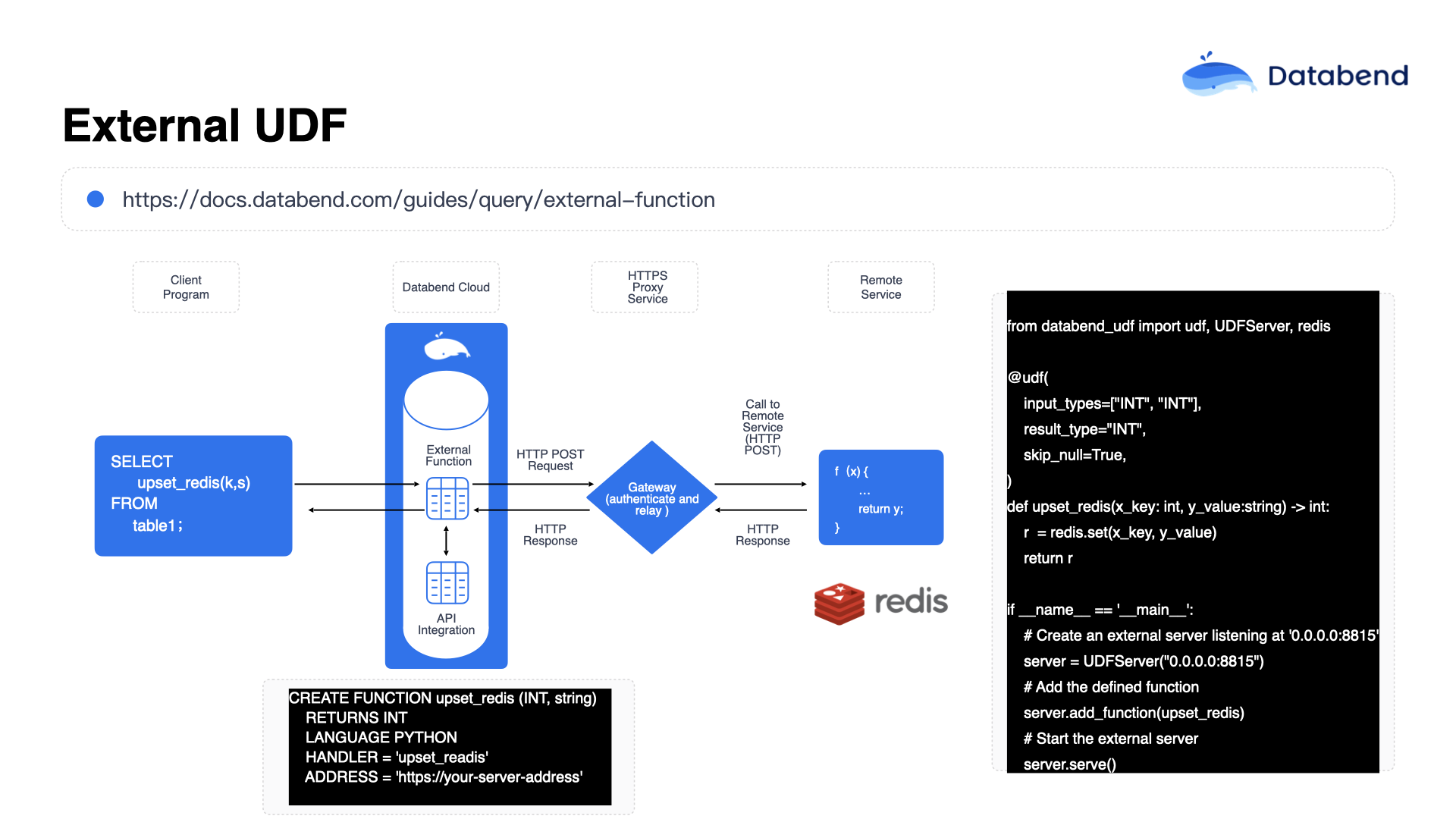
在这个功能的实现过程中,Databend 还做了一些特殊处理:当调用外部 UDF 时,会把数据按照批次(Batch)进行划分,每次以 100 行左右的数据批量调用外部 UDF。之所以这么做,是因为如果你的后端一次性要处理的数据量特别大,比如一次要处理一万行数据,一下子全部压到一个 UDF 中,这个 UDF 很快就会成为性能瓶颈。
但如果以每次 100 行数据的批量调用方式进行处理,那么当后端部署了多个 UDF 节点,比如部署了 10 个 UDF 节点时,每个节点每次只需要处理 100 行数据,这样处理速度会更快,也更加合理。如果出现了瓶颈问题,也可以通过扩展更多的 UDF 服务节点来进行横向扩展。
整体架构类似于这样一个模式:外部可以挂载一些 Lambda 函数,这些 Lambda 函数通过 API Gateway 注册到 Databend 内部形成统一的外部函数,通过这种方式注册和调用,基本可以达到每秒钟调用一次的频率。这样,增量的数据就可以源源不断地实时写入到目标端进行处理。在这种模式下,可以编写非常复杂的算法和业务逻辑,包括如何处理数据以及如何大量地展示数据。
UDF 向 AI 方向的扩展

在以上基础上,Databend 进行了更深入的功能扩展,把 AI 的一些功能融合进来。比如,你可以把 AI 的一些功能封装成函数,然后注册到 Databend 内部,这样就能直接实现近似度检索(Similarity Search)、Embedding 向量计算,甚至 Text-to-SQL(自然语言转 SQL)等功能。
利用流计算实现 ETL 效率的 10 倍性能提升
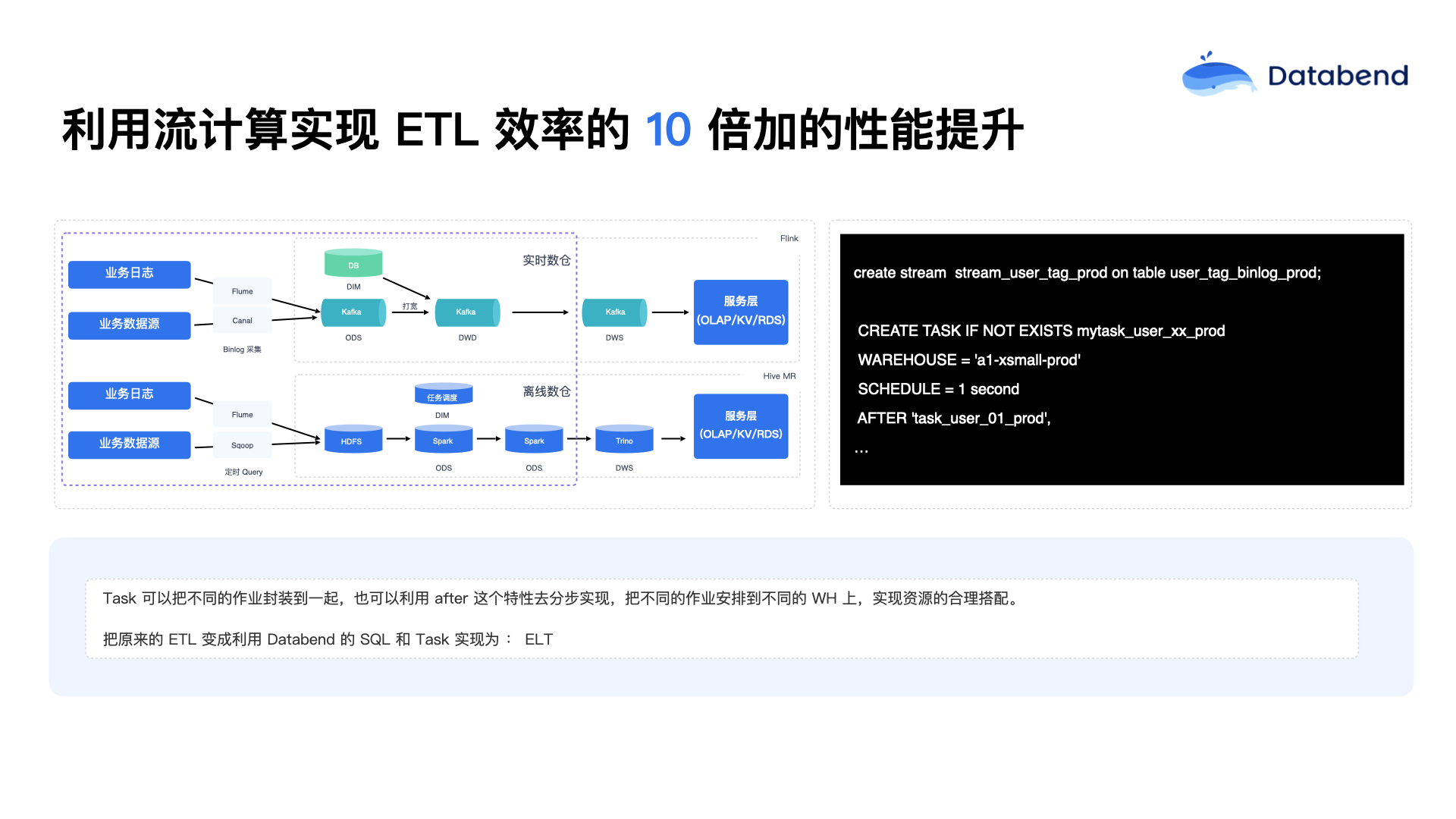
传统大数据习惯称为 ETL,而现在 Databend 体系里更倾向于称为 ELT,也就是说数据原封不动地先进来,然后再通过 Databend 内部的一些任务(Task)进行相应处理。比如传统情况下 binlog 先进入 Kafka,进入 Kafka 之后,通常需要被动地去消费。现在 Databend 提出一种不同的思路,就是 binlog 数据可以直接进入 Databend,然后 Databend 主动地将数据往外推送,形成一种更加主动的推送机制。这种方式利用 Databend 内部明确的记录方式(表级增量捕获)实现了简化的架构。
在这个过程中,用户可以指定不同的计算集群,明确在哪个集群上去执行数据的计算任务,包括任务的调度频率也可以自行定义。目前最小调度粒度是 1 秒钟(相比之下,Snowflake 的最小调度粒度是 1 分钟)。Databend 之所以实现秒级调度,是因为去年接触了一些游戏行业用户,他们对时效性的要求就是秒级。如果任务运行超过 1 秒,就会对外报警,提示用户需要进行扩容或优化,以确保满足秒级响应的需求。
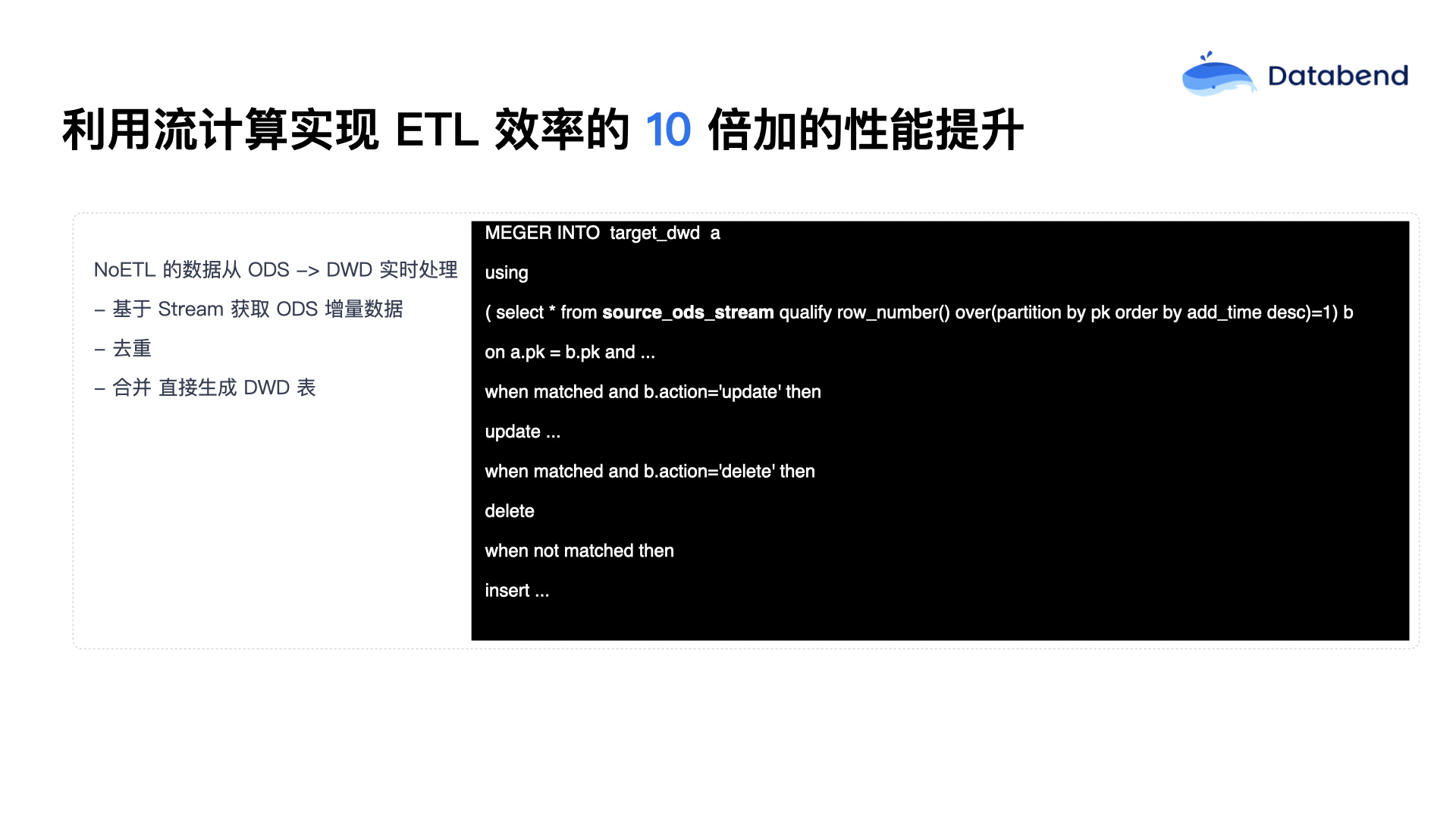
上图展示的是在 ETL 场景下,Databend 如何把数据从 ODS 层迁移到 DWD 层的具体流程:
首先,数据原封不动地进入 Databend,但是需要进行去重处理。去重之后,根据数据的具体动作类型进行不同的处理逻辑。比如,使用
MERGE INTO
row_number
UPDATE
DELETE
INSERT
在项目实践过程中,有一个很有趣的场景:传统大数据团队通常希望 DW 层的数据合并操作在晚上进行,即每天晚上对大量数据进行统一处理。然而后来发现,数据量特别大的时候,往往一个晚上根本处理不完。针对这个问题,现在是将数据合并任务拆分成分钟级的小任务进行处理,结果效果非常不错。在一些规模较大的项目中,某个租户可能拥有上百万张表。如果不将任务拆分得更细致,很多时候任务都无法在有限时间内完成。
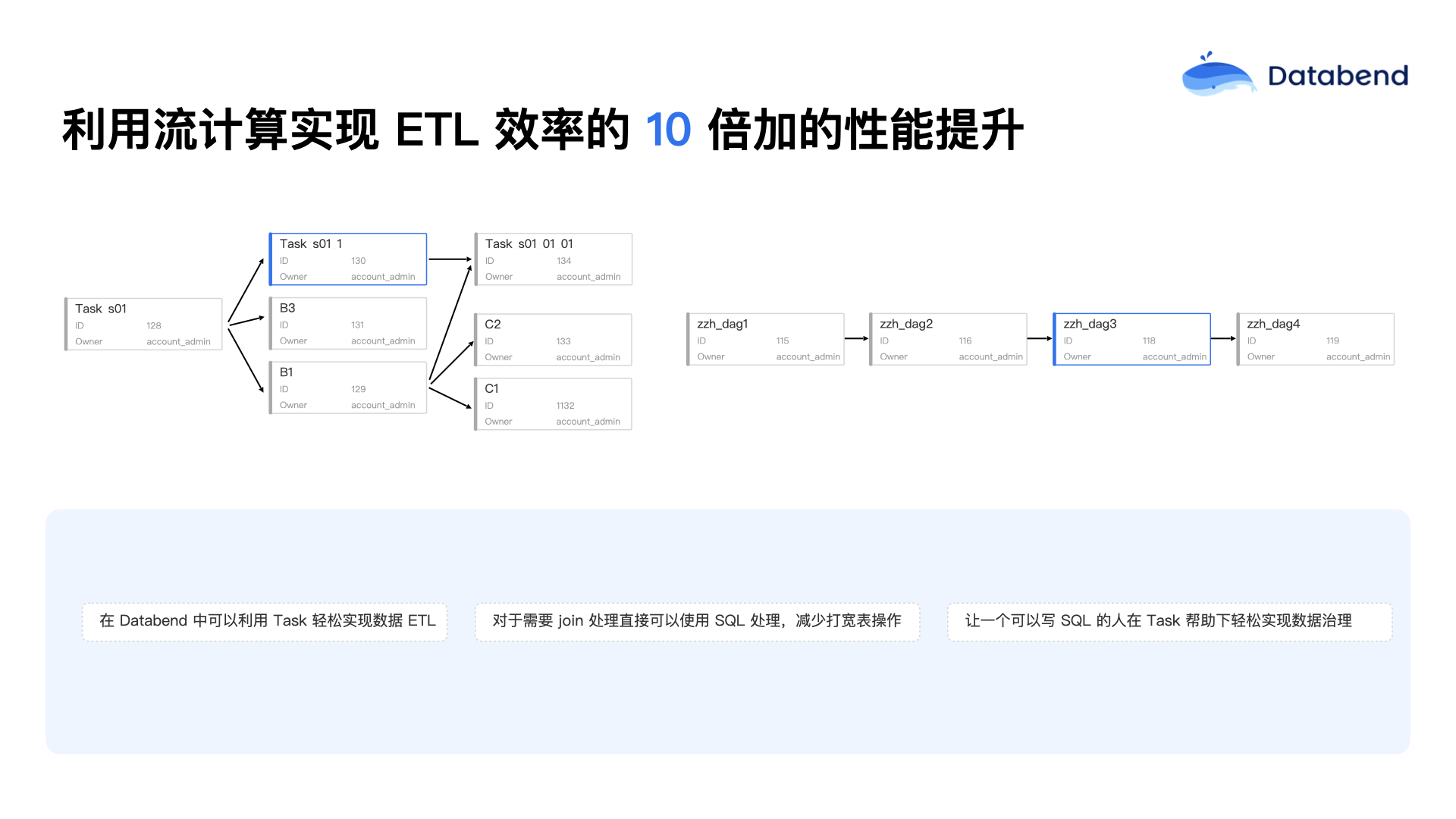
上图是 Databend 云平台提供的任务可视化界面。如果是私有化部署,用户可以借助 Airflow 等工具实现类似的任务可视化功能。这类功能实现相对简单,使用起来也很直观。当任务某个环节出错时,任务的依赖状态会很清晰地展示出来,比如任务之间有前置依赖关系,后面的任务必须等待前面的任务完成后才能运行。这种状态标识、任务的调度,以及出错时的红色告警展示方式,都是需要关注的细节。
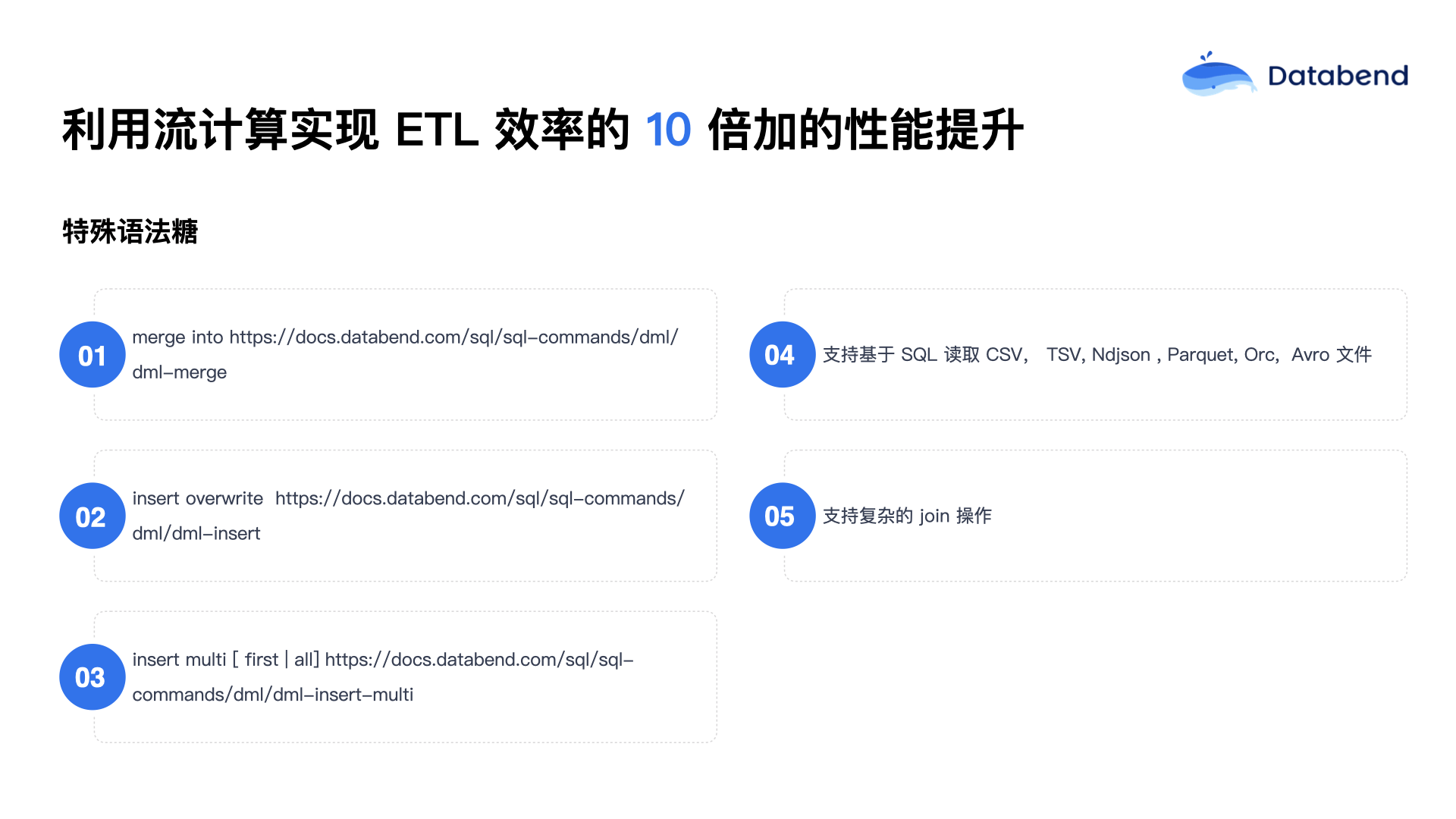
Databend 现在扩展了许多新的 SQL 语法,其中有些新语法是其他数据库中很少见到的,比如
MERGE INTO
INSERT OVERWRITE
INSERT Multi
INSERT Multi
于是 Databend 就推出了
INSERT Multi
INSERT Multi
此外,Databend 还支持直接使用 SQL 从对象存储读取 CSV、TSV、NDJSON、Parquet、ORC、Arrow 等格式文件。这种功能可以基本上取代 Spark 的文件处理工作。过去一些类似产品通常只能处理单个文件,而 Databend 的设计可以通过正则匹配方式一次处理一批文件,极大提高了数据处理的效率。Databend 还特别解决了数据加载过程中的幂等性问题:当把文件写入对应的表中后,在一定时间范围内(默认是 2 天),不允许重复写入同一个文件。如果一定要重复写入,可以通过指定特定参数(如
force
Databend 对复杂的 JOIN 操作也进行了优化。过去没有接触复杂场景时,脑海中的 JOIN 通常是两三张表的关联。但真正接触复杂场景之后才发现,很多 JOIN 都是嵌套查询中再嵌套 JOIN,甚至几十张表同时 JOIN 的情况也很常见。之前在迁移 Greenplum 用户时,就遇到过这样的场景:早期 Databend 产品还不够成熟的时候,生成一个执行计划(EXPLAIN)都需要花费 4 到 5 秒的时间,情况非常糟糕。但现在已经突破了这个瓶颈,即使是极为复杂的 SQL JOIN 操作,也能非常顺畅地处理完成。
数据分析工程师的状态
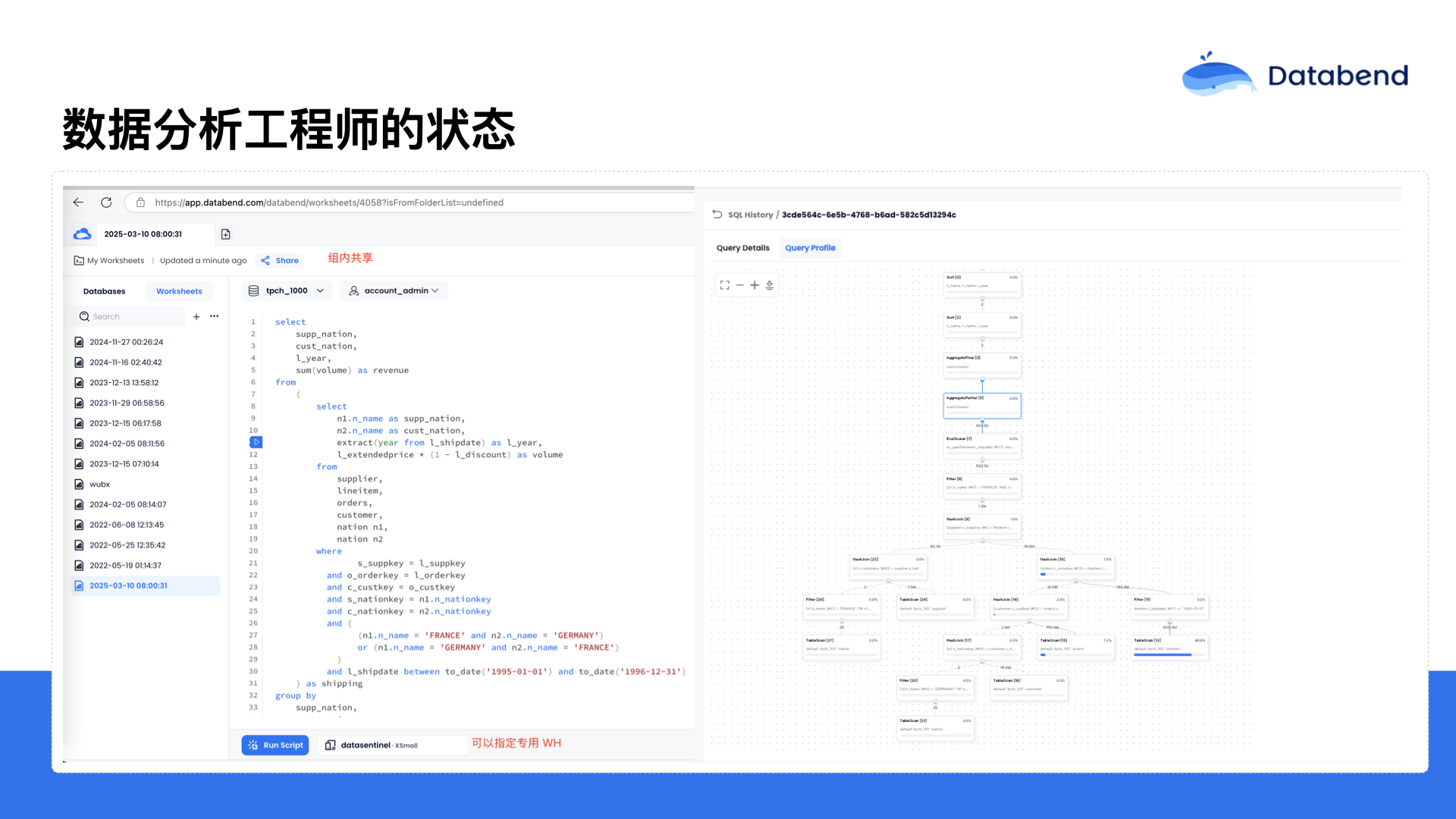
在云平台上,Databend 提供了可视化的 SQL IDE,并且是支持分享的。你在小组内可以与成员共享 SQL 脚本,也可以相互协作。在平台上支持 Dashboard 功能,可以让用户通过 SQL 生成可视化图形展示。
此外,Databend 还提供了可视化的执行计划功能,通过执行计划,可以直观地看到每个 SQL 查询中具体包含哪些算子,每个算子分别花费了多少时间,以此帮助用户进一步优化 SQL 查询性能。这部分功能是由 Databend 团队自主开发的,因此对于整个产品所包含的具体算子情况非常清楚,能够将算子的 Metrics 打印得更详细。这里显示的是详细的 Metrics,比如你和对象存储交互时,每个步骤的响应时间是什么样的,都可以清晰地展示出来,方便用户更好地进行性能分析和优化。
Databend 对游戏行业的优秀特性
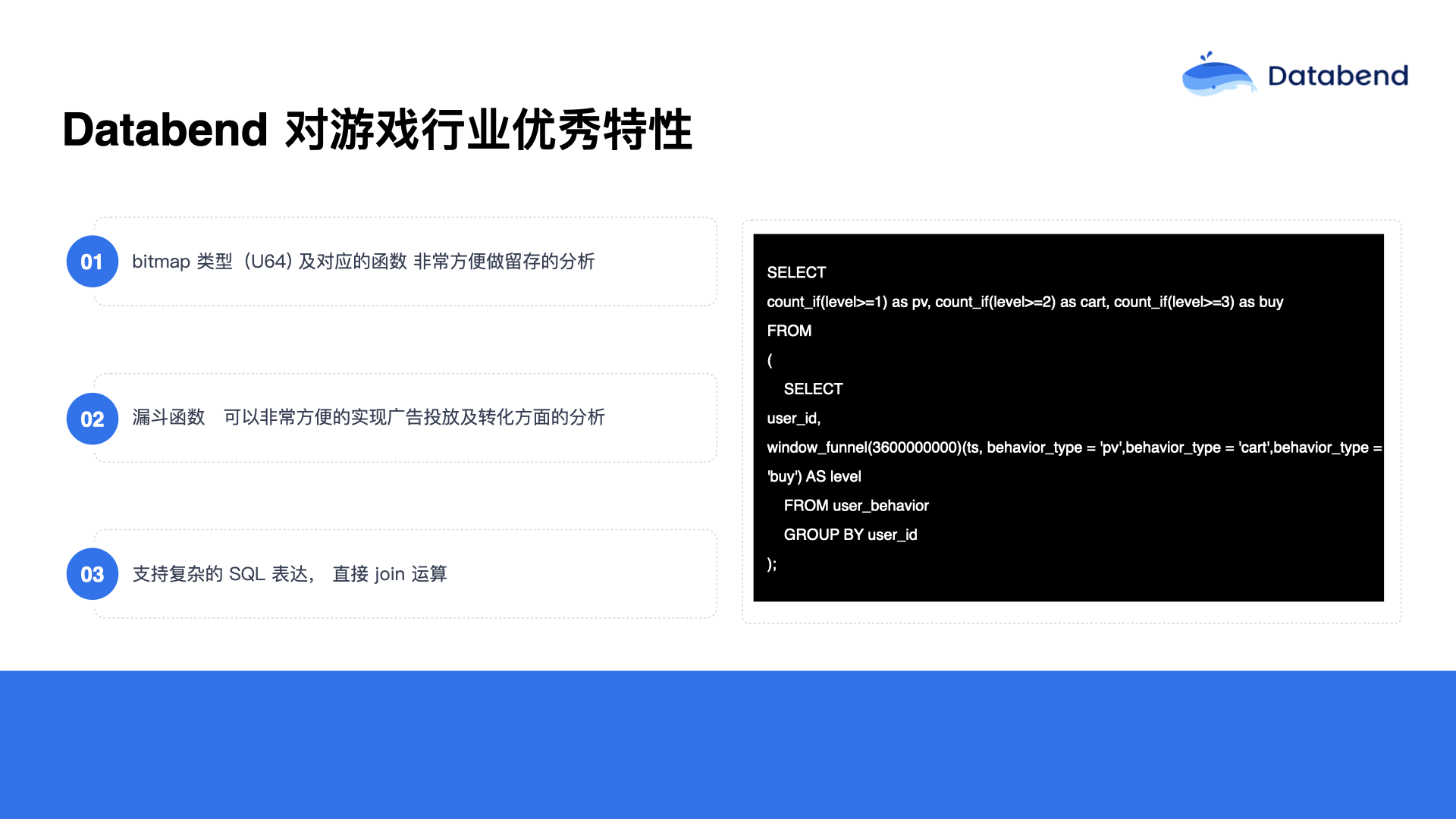
Databend 还在基础数据类型方面做了更多扩展,比如增加了 bitmap 和 Array map 等数据类型,尤其是在数组(Array)类型的处理方面,以前没有专门强调过数组类型,但实际上在大数据领域中数组类型用得非常广泛。比如广告领域经常使用的漏斗函数,用来进行留存分析,通过这种方法可以非常简单地计算出用户的行为路径,比如用户浏览主页后是否添加了商品,是否浏览了某个商品,这些行为是否符合推广预期,这种分析都可以通过数组类型及相应函数轻松实现。
对于复杂的 SQL 表达式,Databend 也支持 Pipeline 式的运算模型,复杂的 SQL 表达式在 Databend 中都可以很好地得到支持。总体而言,Databend 的目标是只要用户会写 SQL,就能在 Databend 中实现任何所需的数据分析动作。
存算分离帮助用户获得更大收益
存算分离大家已经很熟悉,但 Databend 目前所实现的存算分离,已经进入到一个更加先进的阶段。
Databend 做法中有一个可能与很多传统大数据产品不太相同的地方:
- 不提倡用户去使用分区(Partition)。
- 也不强调要建立索引(Index)。
- 甚至不强调用户必须特别注意数据类型的选择。
- 哪怕用户的数据设计中存在 VARCHAR 等不太规范的情况,也完全支持。
在政府行业和移动行业中,大量使用 VARCHAR 字段是很常见的事情,而传统数据库(比如 Oracle)对 VARCHAR 的支持也非常好。因此,每次收到用户的反馈时,也不会过多干预用户的数据设计决策。Databend 内部经常强调的是“无分区、无索引”(No Partition, No Index),但在内部设计了一种称为“Cluster Key”的机制,这一点和 Snowflake 中的 Cluster Key 概念类似。
目前 Databend 提供两种类型的 Cluster Key:
- 一种是 Line Cluster Key,即基于单列的 Order By 排序;
- 另一种是希尔伯特(Hilbert)Cluster Key,即基于多列的 Order By 排序。
使用 Cluster Key 后,在用户对外提供数据服务的场景下,可以有效提升查询性能,尤其适合针对特定列的频繁查询需求。
此外,在混合云场景下,Databend 还能实现计算和存储的彻底分离,比如计算托管在 Databend Cloud 上,而数据存储则位于用户自身的 Bucket 存储中。这种方式给用户提供了更大的灵活性。比如用户后续如果需要迁出云端,只要数据在用户端,迁移起来就会非常便捷。
另外一种场景是,用户可能在内部已经私有化部署了 Databend,但公司内部的数据分析工程师可能会有一些非常复杂的查询需求,这类需求可能需要消耗大量的计算资源。如果公司内部缺乏足够的团队来支持这种大规模资源消耗,用户可以通过将数据以 Attach 的方式直接注册到 Databend Cloud 上,然后利用 Databend Cloud 上强大的计算能力,以直读的方式处理这些数据分析任务。同时,Databend 也提供了高可用性(HA)的解决方案。整体部署架构非常简单。
Databend 逻辑部署架构
Databend 的逻辑部署架构非常精简,目前只有两个核心组件:Databend Meta 和 Databend Query。
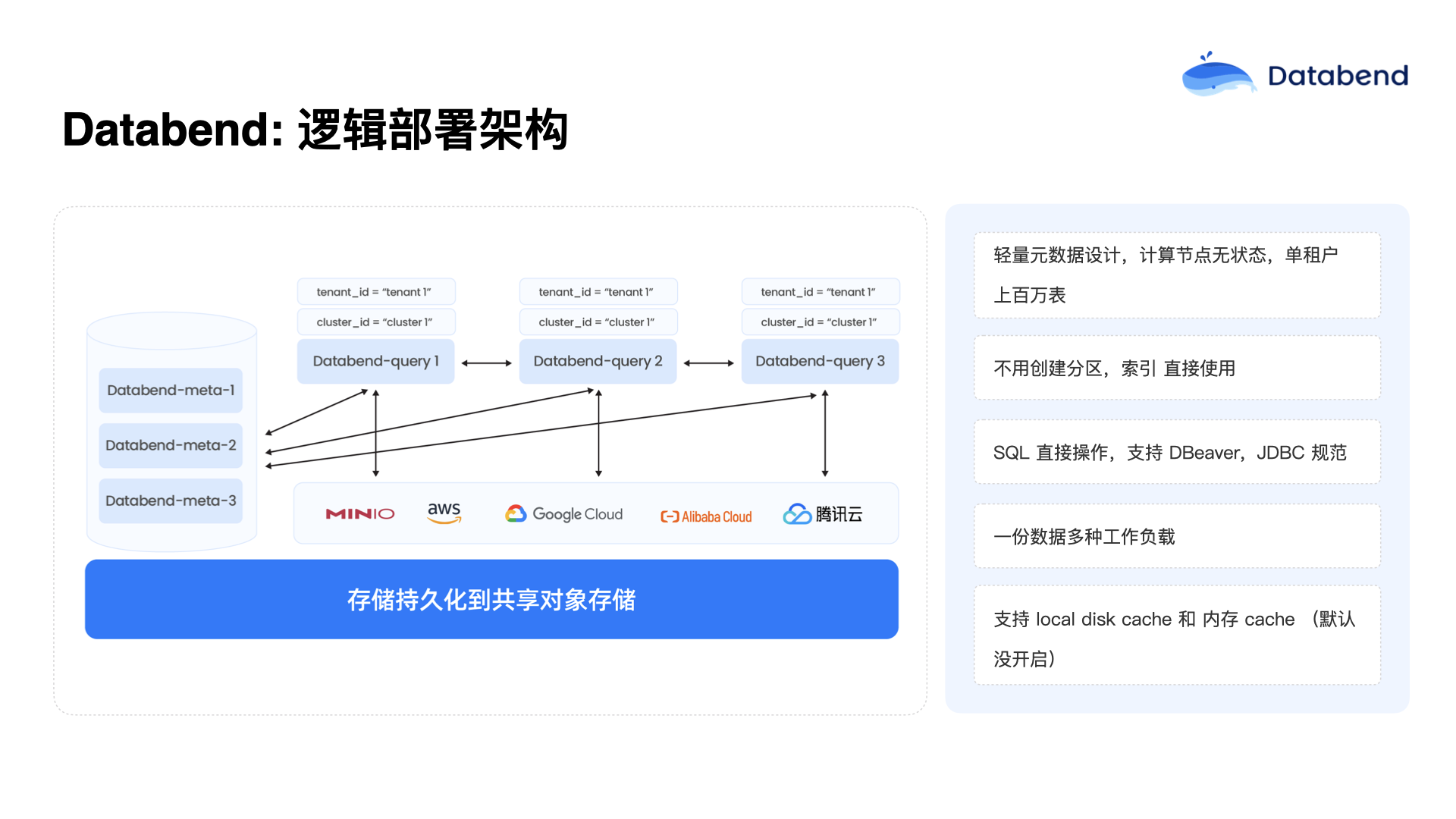
Databend Meta 是元数据系统,这个元数据系统能够稳定地支撑上百万甚至上千万级的元数据量。在实际应用中,一个租户往往可能有超过 100 万张表,总字段数可能达到 4,000 多万个,包括字段的注释、表的注释,这些元数据信息都会被很好地记录下来。大数据系统对注释的依赖非常重,因此在元数据管理方面进行了重点优化,元数据系统运行也非常顺利。
Databend Query 是计算节点,这些计算节点都是无状态的。Databend Query 通过一种标签(Label)的方式来决定为哪个租户或集群提供计算服务。计算节点启动后,会根据自身标签从 Databend Meta 获取对应的权限体系,明确可以访问哪些库、哪些表。同时,计算节点还有一个集群 ID(Cluster ID),这个 ID 决定了它属于哪个集群,并与其他节点共同分担计算负载。
这样的架构有明显优势:用户可以非常方便地实现动态扩展或缩减,根据实际需求灵活组合不同的集群资源。Databend Query 节点基本上可以做到随时启动或关闭,甚至不需要任何状态切换就可以直接关闭,因此升级和维护也非常方便。
Databend 也提供了大量的 Metrics 数据,例如当前运行的查询数量、当前 CPU 占用情况、队列排队情况以及每个查询的响应时间等信息,都会在 Metrics 中清晰展示出来。这些 Metrics 非常便于进行 Kubernetes(K8s)调度和资源分配,目前仍在不断丰富 Metrics 指标体系,已经积累了非常多实用的 Metrics。
此外,Databend 还实现了本地磁盘缓存(Local Disk Cache)和内存缓存(Memory Cache)两种缓存机制,但默认情况下并未开启。如果用户有对外提供实时服务的需求,可以将这两个缓存打开,从而实现更高的性能加速效果。
因此,Databend 的设计理念是使用更小的本地磁盘缓存,通过更多节点水平扩展来提高整体的 IO 性能。用户打开缓存时,只需配备一两百 GB 的缓存空间即可实现较高的 IO 能力。此外,如果用户的内存较大,并且对实时点查有较高需求,可以启用内存缓存。目前在客服系统的实际案例中,用户注册、投诉等各类操作行为查询,通常都能在一秒以内完成响应。在这种场景中,单表字段数动辄超过 1,000 个字段,原本建议用户拆分表结构,但由于客户之前在 ClickHouse 等系统上已经养成了这样的习惯,迁移到 Databend 后依然保持这样的设计,Databend 依旧能很好地支持。
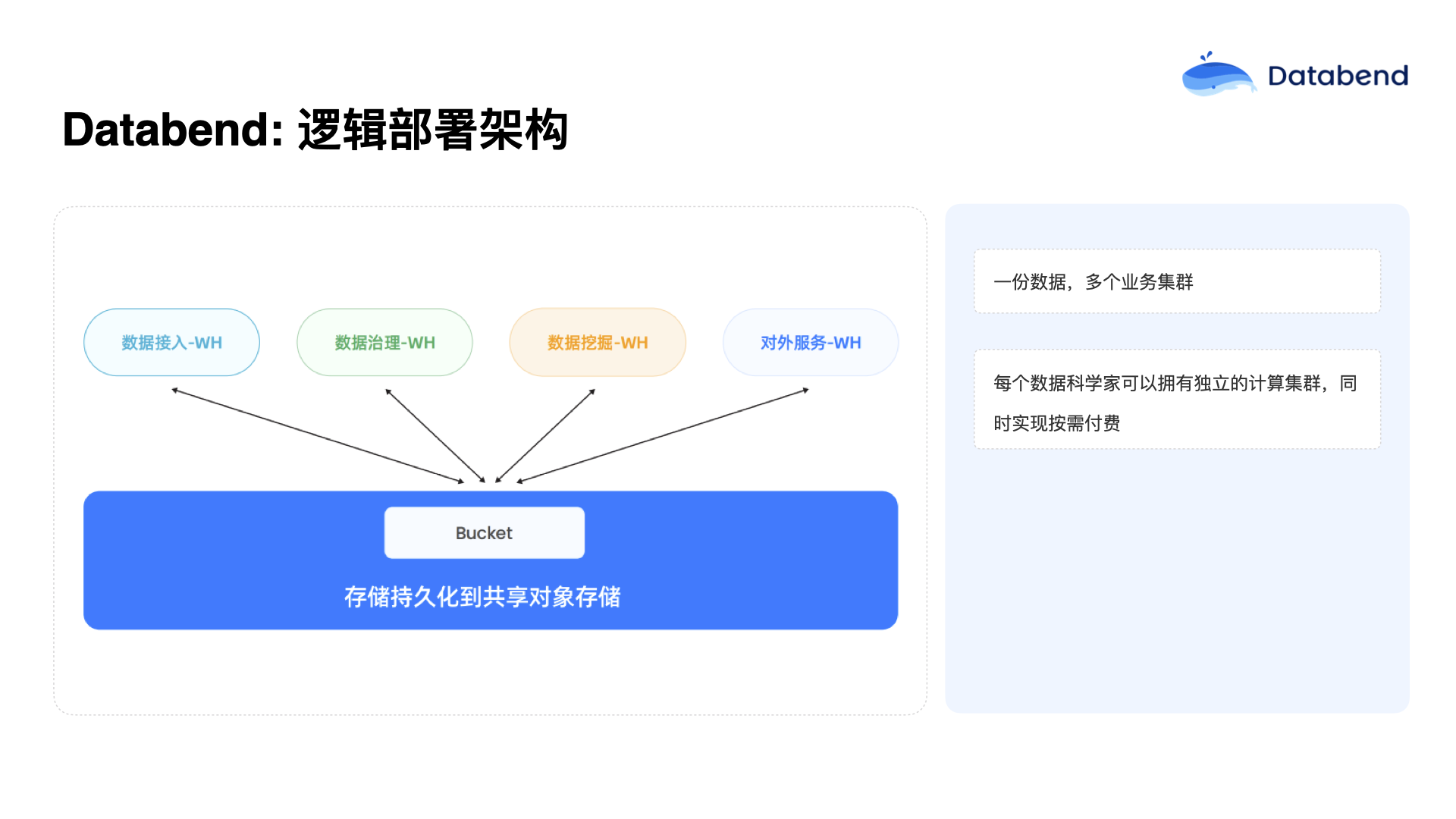
目前,较好的业务实践是:只有一份数据,然后根据不同业务需求拆分成多个集群,这样可以实现更精细化的资源配置。例如,数据接入集群可以很小,仅需几台节点便能源源不断地写入数据;数据治理集群可以规模大一些,甚至只在晚上运行;而数据挖掘团队(数据科学家)可以在白天使用单独的计算集群,通过不同的资源配置方案,在 Kubernetes 中动态调整资源分配。
在 Databend Cloud 云平台中,允许用户自由定义多个 Warehouse(计算仓库),用户用的时候平台会动态地拉起资源,用户不用时资源自动释放,不会产生额外费用。Databend 也不限制用户定义 Warehouse 的数量,用户只需根据实际需求灵活使用即可,只要用户设定好 Warehouse 的休眠时间(例如空闲 5 分钟后自动关闭),就能实现资源使用的动态伸缩。
另外,在对外提供服务的场景中,也可以独立设置集群。这里有一个特别大的挑战,就是大数据系统通常面临对外服务高并发需求的压力。例如,福建省的多个民生服务系统,包括省级办事大厅、“e 福州”、“闽政通”等查询个人医保、公积金、住房贷款等民生数据的平台,这些对外服务场景对并发需求特别高。如果仅仅依靠单一湖仓系统或 ClickHouse,一个节点的并发量一般不会超过 100 左右。
针对这种高并发对外服务场景,Databend 特别推出了一种多集群(Multi-Cluster)架构方案。这种架构可以根据查询响应时间动态扩展集群数量,例如当查询响应时间超过预期值(如设定响应时间为 1 秒,实际响应超过 20%)时,会在用户指定范围内自动增加一个节点并加入集群中,从而缓解压力。根据业务负载,最多可以弹性扩展到 10 个这样的节点。目前,在整个福建省的各类民生服务业务(包括政务大厅、医保、公积金、住房贷款等),都是由 5 个独立节点的集群共同承担,表现非常稳定。
Databend Cloud 重新定义了存算分离
过去说存算分离,通常意味着计算是一层,存储是一层。而 Databend 现在做到的新状态是计算放在 Databend 端,平时用户所使用的 SQL IDE、资源管控,包括资源伸缩等所有内容由 Databend 管理;但数据可以存放在用户自己的桶(Bucket)中。通过这种方式,用户数据在自己的存储中会更加放心。

具体实现方式也很简单,通过创建一个链接指定用户的存储桶位置,然后再创建对应的表关联到存储桶中的数据位置,就可以直接使用数据了。用户在这种模式下也玩出了更多的花样。比如一些用户非常聪明,把实时业务放在 Databend(因为实时业务对资源要求更高),由 Databend Cloud 承担业务最近的实时分析需求。而把离线业务放到自己的环境中运行,因为他们自己有足够的资源进行离线计算。这种方式下,数据的接入和实时计算放在 Databend 侧,而数据存储和离线计算则放在用户自己的环境中进行。此外,用户端数据可以以只读方式快速地挂载到 Databend Cloud 上直接使用,这种方式也给用户带来了很大的便利。这种模式的另一个巨大好处是,即使 Databend Cloud 自身发生严重故障崩溃,用户的数据依然保存在用户端,不会受到任何影响,数据依然完全可见并可以快速恢复。
2023 年,在短视频行业中服务的一家客户就采用了这种模式。当时客户在内部私有化部署了一套 Databend,用于广告投放和数据分析。他们的老板每天盯着这些广告数据情况,一旦有问题可能会立刻打电话过来。同时,他们把核心数据注册到了 Databend Cloud 上,内部的数据分析团队和数据科学家们可以通过 Databend Cloud 自由进行更复杂的数据分析和探索,而不需要影响公司的核心业务系统。这样一来,客户只需要负责核心业务的数据安全和性能保障,数据分析和挖掘等工作可以通过 Databend Cloud 以极低的成本完成。
此外,Databend 持通过 Attach table 的方式,实现云端内部数据的共享和复用。这种直读方式省去了传统大数据领域中大量的数据同步任务。
Databend Cloud 多 IDC 高可用
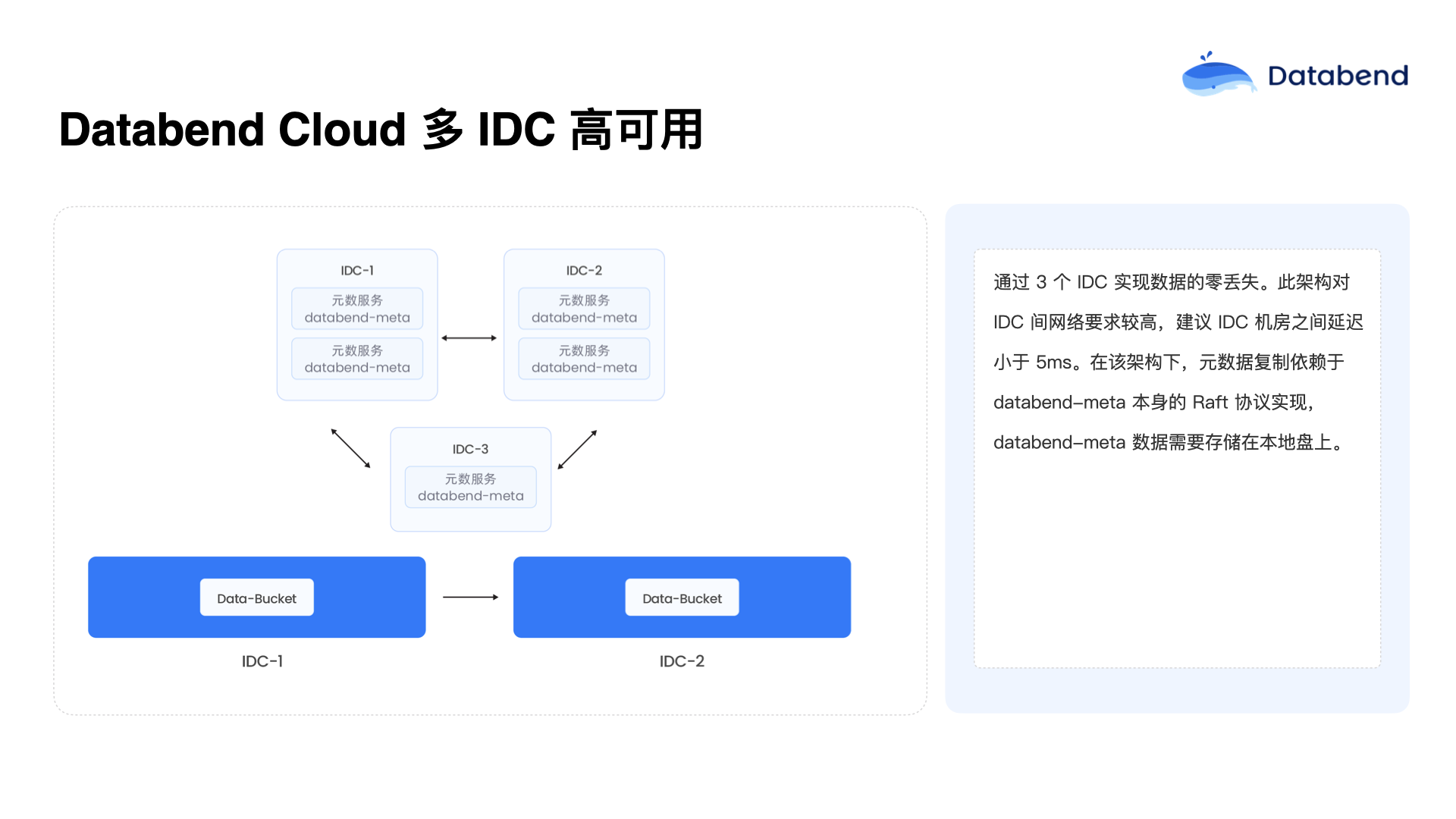
Databend Cloud 的高可用方案,借助了对象存储在云端的一大红利,即用户购买对象存储时可以选择在不同的数据中心之间做数据复制,通过这种方式实现数据在多个 IDC 之间的自动同步和高可用保障。元数据这一层,即使是上百万张表、数千万个字段的规模,数据量实际也并不大,复制起来非常轻松。因此,在三节点甚至三个数据中心之间的同步和复制都非常简单,延迟也很低。
目前 Databend 正在进一步探索,即把元数据直接存放在对象存储中。这样的话,元数据在两个对象存储之间也可以直接实现数据复制。如此一来,计算节点和元数据节点几乎都不需要额外部署,用户可以更加方便地实现多个 IDC 之间的快速部署和数据复制。例如,在其中一个地方的数据中心挂载一个计算集群之后,甚至以只读方式快速拉起,直接对外提供服务是完全可行的。只要不在两个 IDC 同时往数据里写入即可,除非两个对象存储之间也能实现双向复制,那么就可以实现真正的双 IDC 数据写入高可用。
Databend ETL 性能
Databend 使用 Rust 语言实现的 Databend 性能比 ClickHouse 快很多,这个说法引来了 ClickHouse 社区的关注。后来 ClickHouse 的 CTO 也多次发来挑战,质疑为什么不进行一次公开的 Benchmark 测试。

后来在 Databend 0.9 版本时期,在 AWS 的 C6a 裸金属环境下进行了一次严肃的 Benchmark,并且成功提交到了 ClickHouse 社区的性能榜单。众所周知,ClickHouse 社区对 Benchmark 提交要求非常严格。Databend 的成绩在 0.9 版本前顺利提交成功,并且在数据加载性能环节拿到了第一名。
今年,Databend 还针对 Snowflake 进行了 Benchmark 测试。在 TPC-H 100 的场景下,在 AWS 标准节点上的整体性能表现超过了 Snowflake,运行一次 TPC-H 100 测试可能还不到 1 美元。
总结和展望

经过几年发展,Databend 实现的功能和落地场景已经非常多了。Databend 帮助快手替换了原有的 Trino,原本的方案是基于 Trino 直接连接 Hive 进行计算,通过 Hive Catalog 直接接入 Databend 计算,性能提升了 2 到 3 倍,同时成本下降非常明显。
去年,Databend 还帮助用户成功地替换了 Elasticsearch(ES)。原本客户使用数百台 ES 集群,替换后只用了十几台 Databend 节点。同时,以前用户在 ES 中难以完成 Join 操作,或者因为缺少分区导致查询非常慢,现在通过 Databend 用户完全不用关心这些问题了,直接执行 Join 和相关计算即可。
“数据归档”场景是最初多点和 Databend 一同探索落地的。当时并未想到这个场景,没想到效果却非常可观。海外的一些高频交易场景中,用户通常将订单数据归档在 Databend 中,定期再进行分析,用于核验量化交易策略的准确性。过去用户在网站恢复去年订单时需要提交工单,至少一周后才能收到几个 Excel 文件。现在通过 Databend 可以实时查询去年的订单数据,用户使用量也超出了预期,已经远远超过了简单归档的需求,达到了大规模分析和实时查询的程度。
在某个商业场景中,Databend 已经实现了单表 PB 级的数据规模,数据量达到万亿级的行数。这意味着什么呢?例如某工业互联网用户,有一张近万亿行的数据表,原本是用日期加设备 ID 做分区的。有一天该用户只用设备 ID 查询而不使用日期筛选,用 Spark 扩展到 3,000 核,竟然跑了 36 小时。而当用 Databend 时,同样的数据(超过 500 TB)被压缩了近 10 倍,最终只用了大约 30 分钟即完成了查询任务。在表中也同样使用了日期加设备 ID 做为 Cluster Key。虽然用户日常查询大多基于日期,但偶尔基于设备 ID 查询的数据量也非常大。Databend 内部做了许多索引加速,但并未将这些细节暴露给用户,希望用户不必关注太多技术细节,直接使用即可。
Databend 最早的案例之一就是 多点项目,当时也是归档场景。之后,微盟将大量 MySQL 的 binlog 日志迁移过来,每天产生数百 GB 的日志,用于热点字段的分析。茄子快传以及海外的无人机数据采集项目也都在 Databend 上运行。江苏水务的数据采集项目,涉及很多时空数据,也与 Databend 场景很匹配。
当前,业务较多的场景是金融和 Web3 领域,比如钱包标注、区块链数据分析等,数据规模大且要求高效分析。链上投资跟单服务等场景也是 Databend 很适合的领域。其他案例还包括南北医药集团、尼泊尔电信,以及苹果中国选择 Databend 作为替代 Snowflake 的产品。此外,还包括国内汽车领域的头部企业以及 Greenplum 到 Databend 的迁移场景。
2024 年,Databend 也在美国本土的一些医药公司成功部署 Databend。这些都是比较幸运获得的一些头部客户,也是未来几年关注的重点方向。

目前 Databend 特别重视产品的稳定性,因为在大数据领域中用户的 SQL 查询总是超出想象。用户写的 SQL 非常复杂,以前认为等值查询就足够了,但如今实际环境中复杂的窗口函数、嵌套查询层出不穷,复杂度非常惊人。这对在技术和优化方面提出了很高的要求。比如在 TPC-H 中的 CTE 优化、CTE 的物化,以及如何自动化地实现物化视图,这些都是正在深入探索和优化的方向。
此外,Databend 在资源组方面也进行了深入探索,比如如何在有限资源条件下更灵活地实现服务和数据治理的隔离。例如,用户私有化部署了 Databend,只有十台机器,可否在其中创建资源组用于服务,而其他资源组用于治理任务?当业务需求变化需要更多资源时,能否动态地调整机器资源的归属?通过 K8s 及内部资源管控等技术手段,正在进行相应的尝试和优化。
目前在数仓领域遇到了“融合需求”,即如何统一处理结构化数据、半结构化 JSON 数据,以及时空数据。例如前面提到江苏水务巡检场景中,不同日期的照片需要相互对比,涉及时空数据的管理和分析。
**Databend 希望最终构建一个一体化的数据仓库解决方案,能够统一处理离线、实时、地理空间以及 AI 相关的数据分析需求,让数据分析人员的工作更加简单、易用,并真正实现按照使用量付费的理念,达到最低的成本。**经过 4 年的持续打磨,Databend 已经能够很好地覆盖多个场景,因此希望能够更多地与各位朋友交流,进一步探讨新的应用场景。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


