




各位社区小伙伴们,历经数月开发,Databend 于 2023 年 1 月 13 日迎来了 v0.9.0 版本的正式发布!这次新版本是 Databend 迈向 1.0 版本的最后一个大版本,也是迄今为止我们对核心代码重构幅度最大的一个版本!相较于 v0.8.0 版本,开发者们一共新增了 5000 多次 commit,共计700多个优化和修复,涉及4347 个文件变更,约34w行代码修改。感谢各位社区伙伴的参与,以及每一个让 Databend 变得更好的你!
在 v0.9.0 版本中,我们引入了新的类型系统,新的表达式计算框架,JSONB 支持,完整的 join 支持和优化,CBO 支持,Native Storage Format 等主要功能优化,同时性能、稳定性、易用性等方面做了大量优化增强,欢迎大家下载试用。
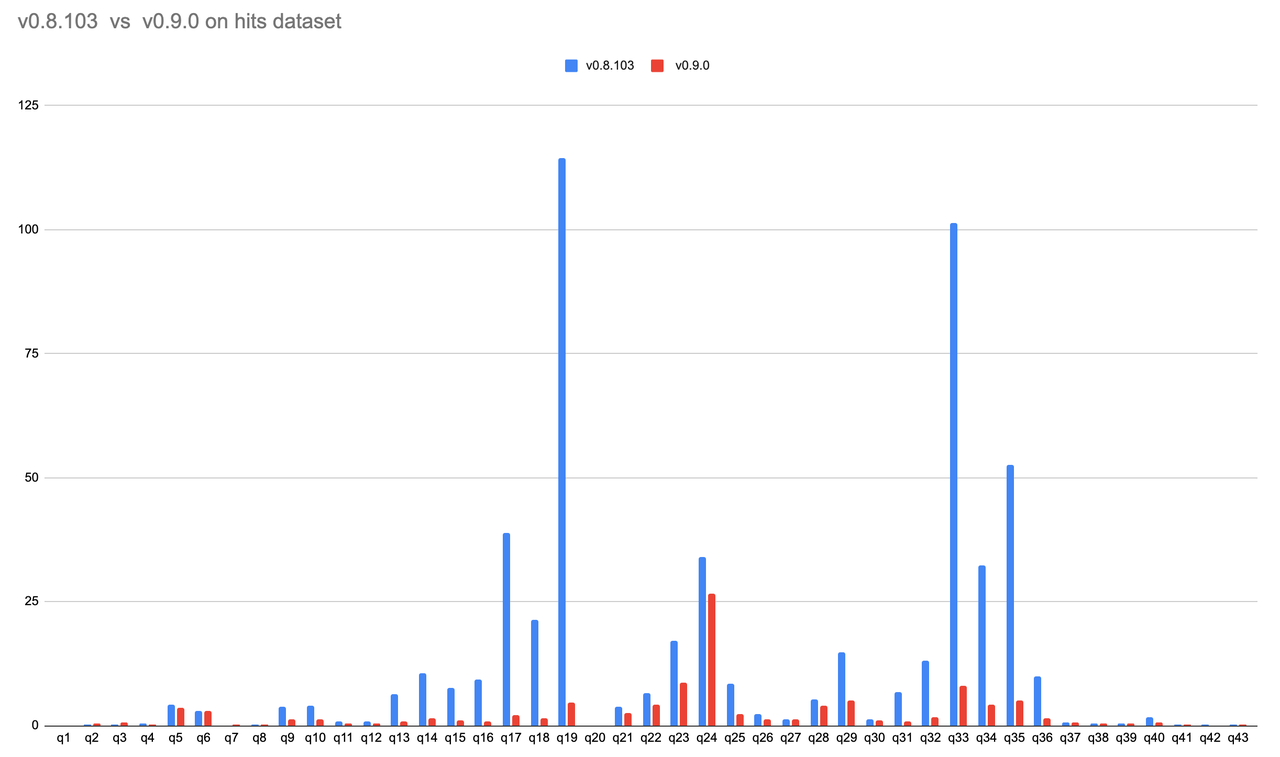
性能对比
在新版本中,我们在执行引擎,优化器,存储层都做了很多优化,大部分场景都有 2 倍以上提升,下面是在 hits 数据集使用 fuse 默认引擎在 s3 存储下两个版本的性能对比
全新的类型系统
为了让 Databend 拥有一个易于理解而又功能强大的类型推导系统,我们借鉴了不少优秀编程语言的编译器内部设计,然后从中精简出适用于 SQL 使用的子集。基于目前的纯静态的类型系统,我们有了完善的类型推导机制,在 SQL 的编译期能尽可能推断出表达式的执行方式,极简的表达式函数注册逻辑,以及在数据库类型级别实现了泛型的推导。
在新的类型系统基础上,常量折叠,类型推导,函数的注册,查询数据裁剪 等模块都能享受到新类型系统带来的红利。 这里有一份简短的介绍:https://zhuanlan.zhihu.com/p/561777236 由于这里太小写不下,不久之后,我们会对此做一个深入的分享,感兴趣的朋友可以关注下。
JSONB 支持
新版本中,我们实现 Rust 版本的 JSONB,默认的 JSON 数据类型 将使用 JSONB 存储,同时也兼容老的 JsonText 格式。基于二进制 JSON 格式,存储空间和查询性能都得到非常明显的优化。

参考:https://docs.databend.cn/doc/contributing/rfcs/json-optimization
完善的 Join SQL 支持
支持完整的 Join types: inner/natural/cross/outer/semi/anti join。
在过去的数月中,针对社区和线上用户的反馈,对 hash join 进行了深度的优化,能够覆盖大多数场景的性能要求。
CBO 支持
在统计信息中,我们加入了 NDV 的统计计算逻辑,用户可以通过类似 presto 的 "Analyze" 命令来生成统计信息表。JOIN 可以利用已有的统计信息,对逻辑计划进行基于代价的优化。后续 CBO 支持完善后,我们会更新 TPCH 100G 数据下的查询性能数据对比。
Native 格式支持
Databend 支持 Git-Like 的 Fuse engine,基于此 engine,我们可以快速回溯到某个历史时间点来查询,在数据库内部实现了 "时间旅行"。而在 Fuse engine 的内部,我们也支持了除 Parquet 之外的 新的 Storage Format --- strawboat: https://github.com/sundy-li/strawboat。 Strawboat 是基于 arrow 的 native storage format,基于它我们在数据读取方面可以做的比 Parquet 更高效,在 hits 数据集中,全表扫 native 格式能快 2-3 倍。在 hits 数据集中,本地部署的场景下取得非常可观的提升,后续我们会完善下性能对比到 clickbench 中。
高效的 bloom filter 过滤
新版本我们引入了 xor filter 来为每个列计算存储 bloom filter,新的 bloom filter 较比之前的版本,导入查询性能,占用空间能都得到了不少优化,参考:https://www.databend.com/blog/xor-filter
设计并开源 serverless DataSharing protocol
实现了基于 object storage presign 短期访问 token 的方式,多租户之间零信任数据共享解决方案。
在基本性能一致的情况下,使用 aws lambda,以 serverless 的方式实现数据共享。
Stage 相关
实现了 UserStage 功能,类似 linux 的 home 目录:
COPY INTO my_table FROM @~;
Stage 的数据导入支持 meta 存储状态,这意味着我们可以一直从 stage 存入新文件来导入 databend;
支持从 Stage 中按不同格式导出多个文件;
从 Stage 导入表支持并行化;
...
其他
除了上面的主要功能外,我们还有其他的新功能或优化点:
-
duckdb 的 read_parquet,支持无需导入,直接读取本地的 parquet 文件
-
常用函数性能优化,常用 GEO 函数支持
-
Distinct 性能优化
-
Adaptive String HashTable
-
SQLancer 对接
-
Parquet 读取加速
-
使用 Rust 重写了之前的 python 版本 sqllogictest
-
NDJSON and JSON output format 支持
-
ALTER TABLE 支持 recluster
-
根据 https://db.in.tum.de/~freitag/papers/p23-freitag-cidr19.pdf,支持 hyperloglog 的更新和删除。 ...
下载使用
如果你对我们新版本功能感兴趣,欢迎来 https://github.com/databendlabs/databend/releases/tag/v0.9.0-nightly 页面查看全部的 changelog 或者 下载 release 体验。
如果你在使用旧版本的 Databend,你可以直接升级到新版本,升级过程请参考:https://docs.databend.cn/doc/operations/upgrade
意见反馈
如果您遇到任何使用上的问题,欢迎随时通过 GitHub issue 或社区用户群中提建议
GitHub: https://github.com/databendlabs/databend/
致谢
最后感谢参与新版本设计开发,测试,文档贡献的开发者们。
感谢有你们 (GitHub 昵称排序):

订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


