




该文章来自 吴炳锡 在 IFClub 福州站分享回顾。
过去这些年,企业建设数据平台,基本都围绕几个关键词展开:存储、计算、分析、成本。所以我们看到了从单机数据库到 Hadoop,再到湖仓一体的持续演进。每一次升级,本质上都在解决同一个问题:如何更高效地管理越来越多的数据。但 AI 的出现,让这件事开始变得不一样。 今天企业真正关心的,已经不只是“数据能不能存、能不能查”,而是数据能不能更高效地被 AI 理解、调用,并最终转化为业务结果。这也是为什么,很多团队明明已经完成了湖仓建设,在当前 AI 时代却依然会觉得现有的数据底座“不够用了”。

湖仓解决了很多问题,但没解决 AI 的问题

湖仓一体解决了存储和分析的问题,却没有天然解决 AI 落地时最麻烦的那部分工作。因为在真实业务里,最有价值的数据并不总是整齐地躺在表里。PDF、日志、文档、图片、账单、聊天记录、录音,这些非结构化数据才是企业知识、流程和经验的主要载体。但在传统架构里,它们往往分散在对象存储、文件系统和业务应用中,很难和结构化数据一起被统一分析。
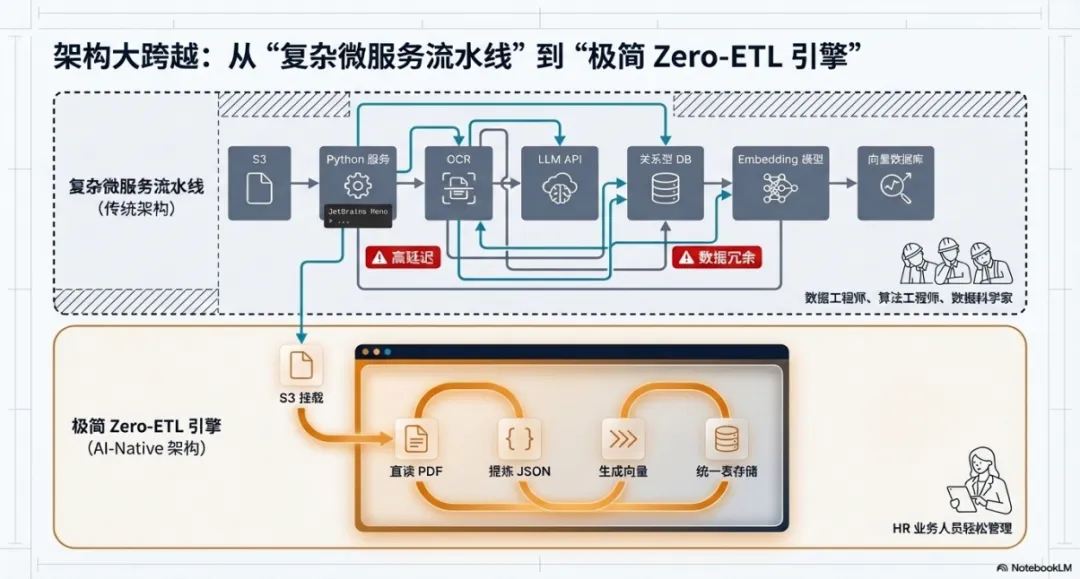
于是很多 AI 项目一上来就会进入熟悉的流程:
- 先抽取文件
- 再做 OCR 或解析
- 再做清洗
- 再调用模型
- 再做向量化
- 再入向量库
最后再回头和数仓里的结构化数据做关联 流程当然能跑,但问题也很明显:
- 链路太长
- 数据搬运太重
- 副本越来越多
- 系统之间耦合越来越复杂
一旦业务场景增加,维护成本就会快速上升 所以很多企业并不是缺一个模型,而是缺一个真正适合 AI 工作方式的新型数据底座。

这次分享里提出的一个关键判断是:
AI-Native 数仓,不是给传统数仓加一个大模型接口,而是从底层开始,让 AI 成为数据系统的一等能力。
如果进一步拆开看,它至少意味着三件事。
第一,数据系统要天然支持多模态。
未来的数据平台不能只围绕结构化表设计。JSON、文本、向量、文档,甚至文件本身,都应该进入同一套处理和分析体系。只有这样,AI 才能真正建立在企业完整的数据上下文之上。
第二,AI 要尽量靠近数据,而不是让数据反复搬家。
过去很多链路的问题,并不是模型能力不够,而是数据离模型太远。解析、抽取、向量化、分析,如果都要靠外部服务拼接,复杂度会非常高。更合理的方式,是把更多能力沉到数据系统附近,让链路变短,让执行更统一。
第三,Agent 不该绕开数仓,而应该直接调用数仓能力。
未来很多交互会从自然语言开始,但自然语言只是入口。真正决定结果质量的,是 Agent 背后有没有可靠的工具链。如果模型只靠自己猜,结果很难稳定;如果它能调用 Databend 这样的湖仓产品进行精确计算,整个系统的可靠性就会高很多。

两个例子,AI4DB & DB4AI 在 Databend 中整合
AI4DB: HR 做简单筛选及候选人推荐。
每天面对海量的简历及人员,如何能高效的找到千里马呢?

利用 Databend 一个 SQL 把非结构化的简历,半结构化及向量的资源,供后续的 AI 使用:
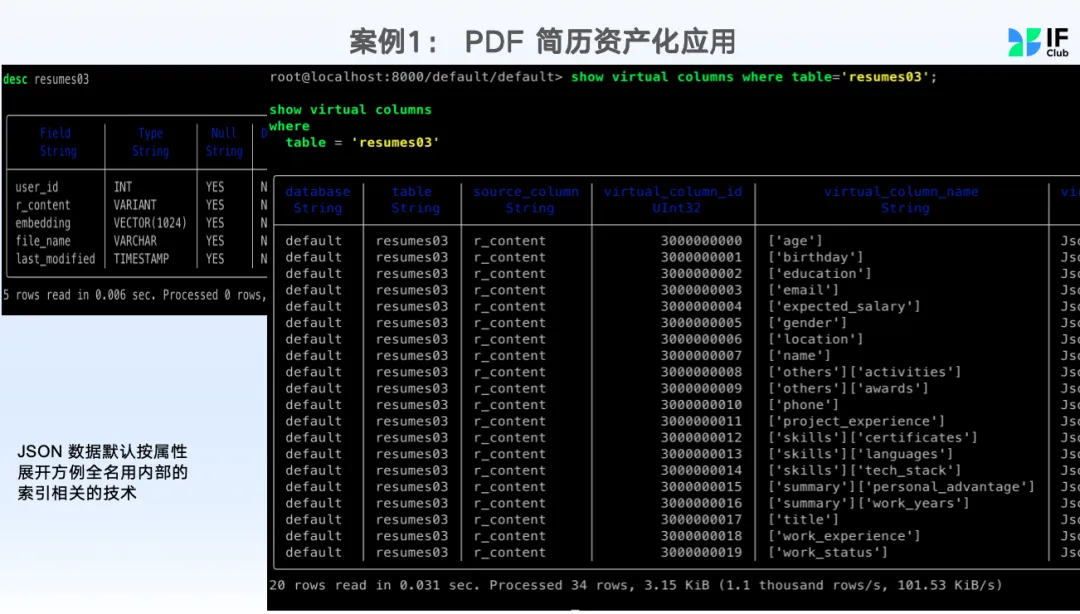
在此基础上,后续流程就会清晰很多,形成资产后,可以让 AI 用自然语言从资产表中去利用全文搜索 + 向量检索,针对推荐的候选人,再加上 HR 的招聘要求,让 AI 打分推送。可以下面的视频:
该案例小结:
利用 AI 完成数据清洗和核心信息提炼,可以让原本混乱的非结构化数据变得更易读、也更易用。同样结合 Databend 本身的全文检索,json 能力,vector 能力,给 AI 提供一条高效的数据处理通路。两者结合给出一个更完全的解决方案。
DB4AI 利用 Databend 去分析阿里云的账单

云平台会提供丰富的报表和账单,帮助你了解费用花在了哪里,但从来不会讲你花的这次钱有没有浪费。我们面对这些账单天生字段多、结构复杂,又难于分析。如果直接把原始数据丢给大模型,很容易出现幻觉,也容易受到上下文窗口限制。更好的方式,是让模型负责理解问题,让数仓负责做聚合、筛选和计算。模型和 Databend 这样的分析引擎协同起来,才能真正把“会回答”变成“答得准”。接下看视频给演示了账单加到 Databend 后 , AI 基于 mcp_databend 调用进行账单分析。
在 https://app.databend.cn/ 注册后可以直接体验,熟练人员大概 10 分钟就能完成。如果你对想利用 Databend Cloud 分主析云账单,获得支持也可以微信加到:Databend 获得支持。
该案例小结:
- 业务挑战:阿里云账单位明细极其复杂。大模型直接读取存在严重“幻觉”问题与上下文 Token 限制
- 破局思路:大模型利用 MPC 访问 Databend 提供结构化数据,让 LLM 的意图推理与 Databend 的极速 OLAP 算力完美结合与协同,发挥出更大的威力。无须关注数据长度 & 无须关注分区 & 无须关注索引
从“湖仓”到“智算”,真正变化的是角色
很多人会把这件事理解成一次技术栈升级,但它更深层的变化,其实是数据平台角色的变化。过去,数据平台更像一个“冷库”和“加工厂”。现在,它开始变成业务的智能计算底座:
- 不只是存数据,也要理解数据
- 不只是支撑分析,也要支撑 Agent 调用
- 不只是回答过去发生了什么,也要参与下一步行动 这就是“从湖仓到智算”真正想表达的东西。
AI 时代的数据平台竞争,最终比的不会只是性能和成本,还会比谁更能把数据、模型和计算放进一个统一而高效的协作体系。对企业来说,真正重要的不是多接了一个模型接口,而是有没有能力让数据底座从“支撑分析”走向“支撑智能执行”。 这件事,值得所有正在重做数据平台的人重新思考一遍:未来的 AI-Native 云原生数据底座,究竟该如何建设?
关于 Databend
Databend 是一款 100% Rust 构建、面向对象存储设计的新一代开源云原生数据仓库,统一支持 BI 分析、AI 向量、全文检索及地理空间分析等多模态能力。
期待您的关注,一起打造新一代开源 AI + Data Cloud。
👨💻 Databend Cloud:https://databend.cn
📖 Databend 文档:https://docs.databend.cn
💻Wechat:Databend
✨GitHub:https://github.com/databendlabs/databend
使用 Databend Cloud 天然解决 AI 落地烦恼
开始使用 Databend Cloud——面向分析、搜索、AI 与 Python Sandbox 的 Agent Ready 数仓,即可开始,获得 200 元代金券。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


