




Databend 云原生湖仓同时支持私有化和公有云两种部署形态,因此在写入方式上也共提供了4方式种选择。本文一方面通过性能测试认识不同形态的性能差异,另一方面也尝试理解这些设计背后的原因,进而体会如何结合业务场景选择最适合的写入方式。
Databend 支持的写入方式
Databend 提供了 4 种数据写入方式,适用于不同的部署场景:
1. INSERT (Bulk Insert with Presign)
对象存储可以直接对应用开放,支持 presign 模式。适用于云上场景, 可以充分发挥对象存储写入数据不收流量费的特点。
简称:
insert
2. INSERT_NO_PRESIGN
对象存储不能直接对应用开放,数据通过 Databend 节点转发。适用于私有化场景。
简称:
insert_no_presign
3. STREAMING_LOAD
支持 CSV、NDJSON、Parquet 等常见格式直接流式写入,是私有化场景里接受度较高的一种形态。适用于实时数据摄入。
简称:
streaming_load
4. STAGE_LOAD (Copy Into)
基于对象存储的批量加载,可以处理 CSV、NDJSON、Parquet、ORC 等文件及其压缩格式。这是性能最强的云原生写入方式。
简称:
stage_load
💡 提示: 这四种方式都可以直接通过 Java 调用
实现
💻 代码示例
1. INSERT (Bulk Insert)
适用场景: 云上场景,对象存储可对应用开放
Properties props = new Properties();
props.setProperty("user", "root");
props.setProperty("password", "password");
try (Connection conn = DriverManager.getConnection("jdbc:databend://host:8000/db", props)) {
conn.setAutoCommit(false);
String sql = "INSERT INTO bench_insert (id, name, birthday, address, ...) VALUES (?, ?, ?, ?, ...)";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
// 批量插入
for (int i = 0; i < batchSize; i++) {
ps.setLong(1, i);
ps.setString(2, "name_" + i);
ps.setString(3, "2024-01-01");
ps.setString(4, "address_" + i);
// ... 设置其他字段
ps.addBatch();
}
ps.executeBatch(); // 执行批量插入
}
}
特点:
- 使用 presign URL,数据直接写入对象存储
- 适合云上场景,降低网络成本
2. INSERT_NO_PRESIGN
适用场景: 私有化场景,对象存储不能直接对应用开放
Properties props = new Properties();
props.setProperty("user", "root");
props.setProperty("password", "password");
props.setProperty("presigned_url_disabled", "true"); // 关键配置:禁用 presign
try (Connection conn = DriverManager.getConnection("jdbc:databend://host:8000/db", props)) {
conn.setAutoCommit(false);
String sql = "INSERT INTO bench_insert (id, name, birthday, ...) VALUES (?, ?, ?, ...)";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
for (int i = 0; i < batchSize; i++) {
ps.setLong(1, i);
ps.setString(2, "name_" + i);
// ... 设置其他字段
ps.addBatch();
}
ps.executeBatch();
}
}
特点:
- 只需在连接串中加 ,无需其他改动presigned_url_disabled=true
- 数据通过 Databend 节点转发到对象存储
3. STREAMING_LOAD
适用场景: 私有化实时写入,支持多种格式
import com.databend.jdbc.DatabendConnection;
import com.databend.jdbc.DatabendConnectionExtension;
Properties props = new Properties();
props.setProperty("user", "root");
props.setProperty("password", "password");
try (Connection conn = DriverManager.getConnection("jdbc:databend://host:8000/db", props)) {
DatabendConnection databendConn = conn.unwrap(DatabendConnection.class);
// 构造 CSV 数据
String csvData = """
1,batch_1,name_1,2024-01-01,address_1,...
2,batch_1,name_2,2024-01-01,address_2,...
3,batch_1,name_3,2024-01-01,address_3,...
""";
byte[] payload = csvData.getBytes(StandardCharsets.UTF_8);
try (InputStream in = new ByteArrayInputStream(payload)) {
String sql = "INSERT INTO bench_insert FROM @_databend_load FILE_FORMAT=(type=CSV)";
int loaded = databendConn.loadStreamToTable(
sql,
in,
payload.length,
DatabendConnectionExtension.LoadMethod.STREAMING
);
System.out.println("Loaded rows: " + loaded);
}
}
特点:
- 使用特殊 stage ,直接流式加载@_databend_load
- 支持 CSV/NDJSON/Parquet/Orc 等格式
- 吞吐随 batch 增大快速提升
4. STAGE_LOAD (Copy Into)
适用场景: 大批量数据加载,最高性能
import org.apache.opendal.AsyncOperator;
// 1. 创建 S3 Operator (使用 OpenDAL)
Map<String, String> conf = new HashMap<>();
conf.put("bucket", "my-bucket");
conf.put("endpoint", "http://s3-endpoint:9000");
conf.put("access_key_id", "access_key");
conf.put("secret_access_key", "secret_key");
try (AsyncOperator op = AsyncOperator.of("s3", conf);
Connection conn = DriverManager.getConnection("jdbc:databend://host:8000/db", user, password)) {
// 2. 创建 External Stage
String createStage = """
CREATE STAGE IF NOT EXISTS my_stage
URL='s3://my-bucket/data/'
CONNECTION=(
endpoint_url = 'http://s3-endpoint:9000'
access_key_id = 'access_key'
secret_access_key = 'secret_key'
)
""";
conn.createStatement().execute(createStage);
// 3. 写入数据到对象存储
String csvData = "1,name1,2024-01-01,...\n2,name2,2024-01-01,...\n";
byte[] payload = csvData.getBytes(StandardCharsets.UTF_8);
op.write("batch_001.csv", payload).join();
// 4. 使用 COPY INTO 批量加载
String copySql = """
COPY INTO bench_insert
FROM @my_stage
PATTERN='.*\\.csv'
FILE_FORMAT=(type=CSV)
PURGE=TRUE
""";
conn.createStatement().execute(copySql);
}
特点:
- 数据先写对象存储,再批量加载,充分利用对象存储并行能力
- 云上场景节省网络成本(对象存储读写不收费)
本次测试方案
- 平台: 某集团国产信创环境
- 工具: Java + databend-jdbc
压测程序借助 AI 自动生成,这里不再赘述,可直接参考脚本: https://github.com/wubx/databend_ingestion/tree/main/db_ingestion
表结构
- 数据: Mock 数据,23 个字段(包含 VARCHAR、DATE、TIMESTAMP 等类型)
CREATE OR REPLACE TABLE bench_insert (
id BIGINT,
batch VARCHAR,
name VARCHAR,
birthday DATE,
address VARCHAR,
company VARCHAR,
job VARCHAR,
bank VARCHAR,
password VARCHAR,
phone_number VARCHAR,
user_agent VARCHAR,
c1 VARCHAR,
c2 VARCHAR,
c3 VARCHAR,
c4 VARCHAR,
c5 VARCHAR,
c6 VARCHAR,
c7 VARCHAR,
c8 VARCHAR,
c9 VARCHAR,
c10 VARCHAR,
d DATE,
t TIMESTAMP
)
压测
for bt in 2000 3000 4000 5000 10000 20000 30000 40000 50000 100000 200000
do
for type in insert insert_no_presign streaming_load stage_load
do
echo $bt $type
java -Dfile.encoding=UTF-8 -Dsun.stdout.encoding=UTF-8 -Dsun.stderr.encoding=UTF-8 -jar ./db_ingestion-1.0-SNAPSHOT-shaded.jar $type 2000000 $bt
done
done
结果分析
INSERT vs STREAMING_LOAD 性能对比
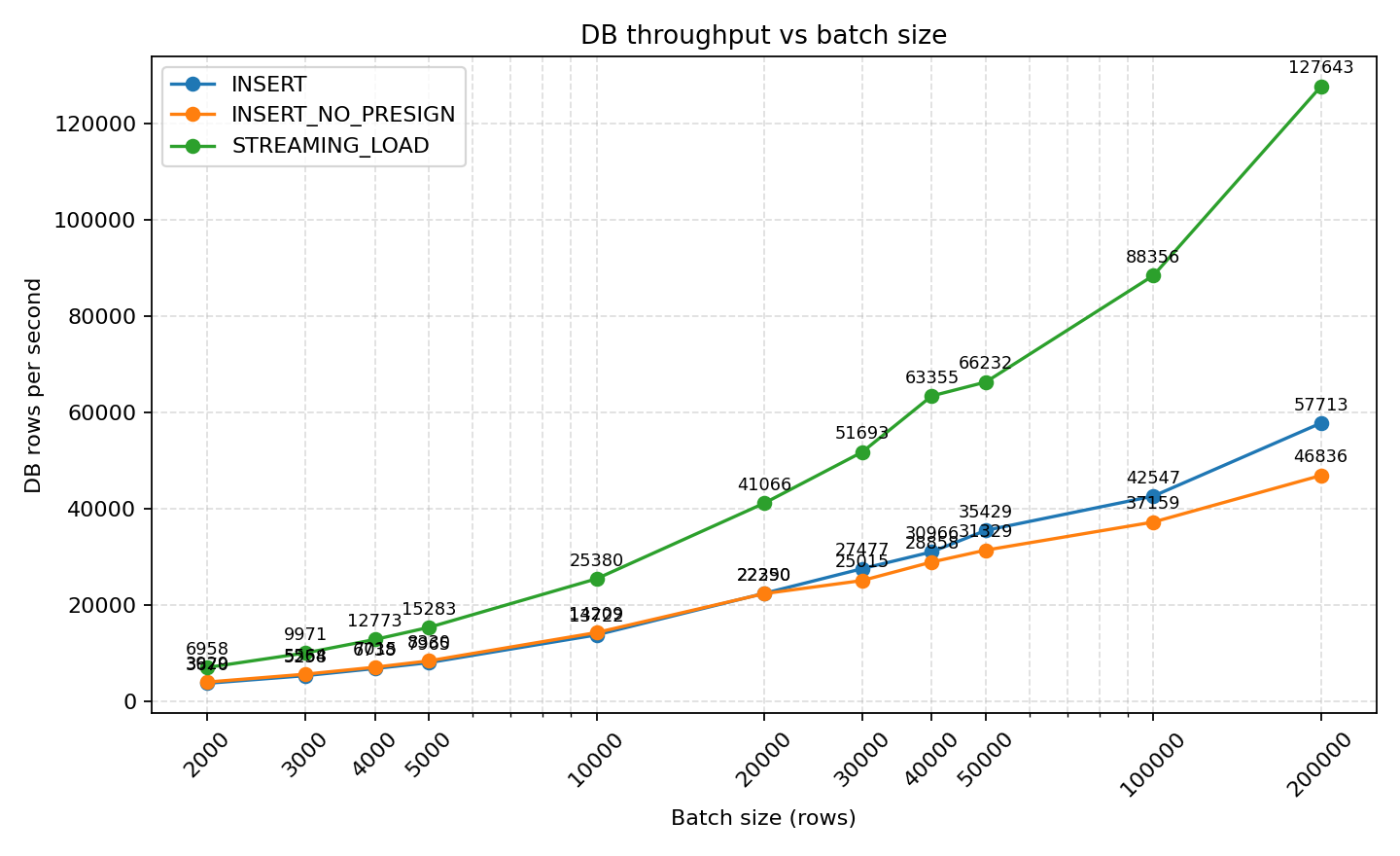
- STREAMING_LOAD 的 DB 吞吐随着 batch 增大快速提升,从 2k 批的 6,958 rows/s 提升至 200k 批的 127,643 rows/s,明显优于同批次的 INSERT(29,283 rows/s)和 INSERT_NO_PRESIGN(26,121 rows/s)。
- INSERT 与 INSERT_NO_PRESIGN 在小批次差距尚可(batch=2k 时 3,670 vs 3,929 rows/s),但 ≥20k 后几乎重合,且总体被 streaming 方案压制。
关键发现:
- STREAMING_LOAD 的 DB 吞吐随着 batch 增大快速提升:
- 2k batch: 6,958 rows/s
- 200k batch: 127,643 rows/s
- INSERT 和 INSERT_NO_PRESIGN 性能相近:
- 小批次(2k)时差距不大:3,670 vs 3,929 rows/s
- ≥20k batch 后几乎重合,后续随着 Batch 增大后,INSERT WITH Presign 模式性能表现的更好
- 200k batch 时:INSERT ~29,283 rows/s,INSERT_NO_PRESIGN ~26,121 rows/s
- Streaming_load 性能整体优于 INSERT, INSERT_NO_PERSIGN
STAGE_LOAD (Copy Into) 性能
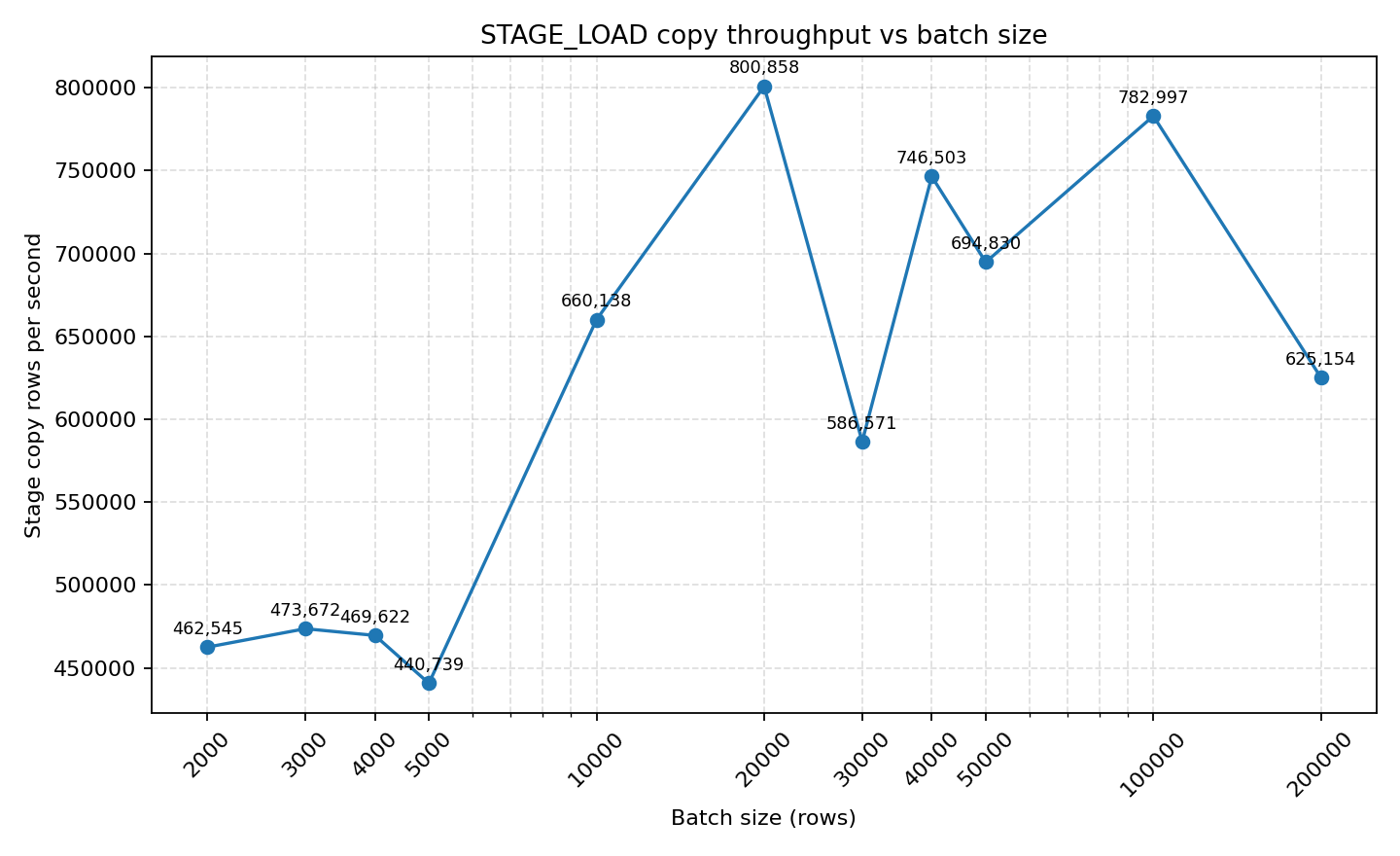
- STAGE_LOAD 的 COPY throughput 处于另一个量级:batch=20k 时即达到 800k rows/s,50k 批稳定在 694k rows/s。整个阶段的总耗时受 stage 写入 + copy 启动占比影响更大,但单次 COPY 的吞吐无可比拟。
关键发现:
- COPY INTO 容易受到网络带宽瓶颈的限制
- 整体耗时受 stage 写入 + copy 启动开销影响,但单次 COPY 的吞吐无可比拟
四种方式综合对比
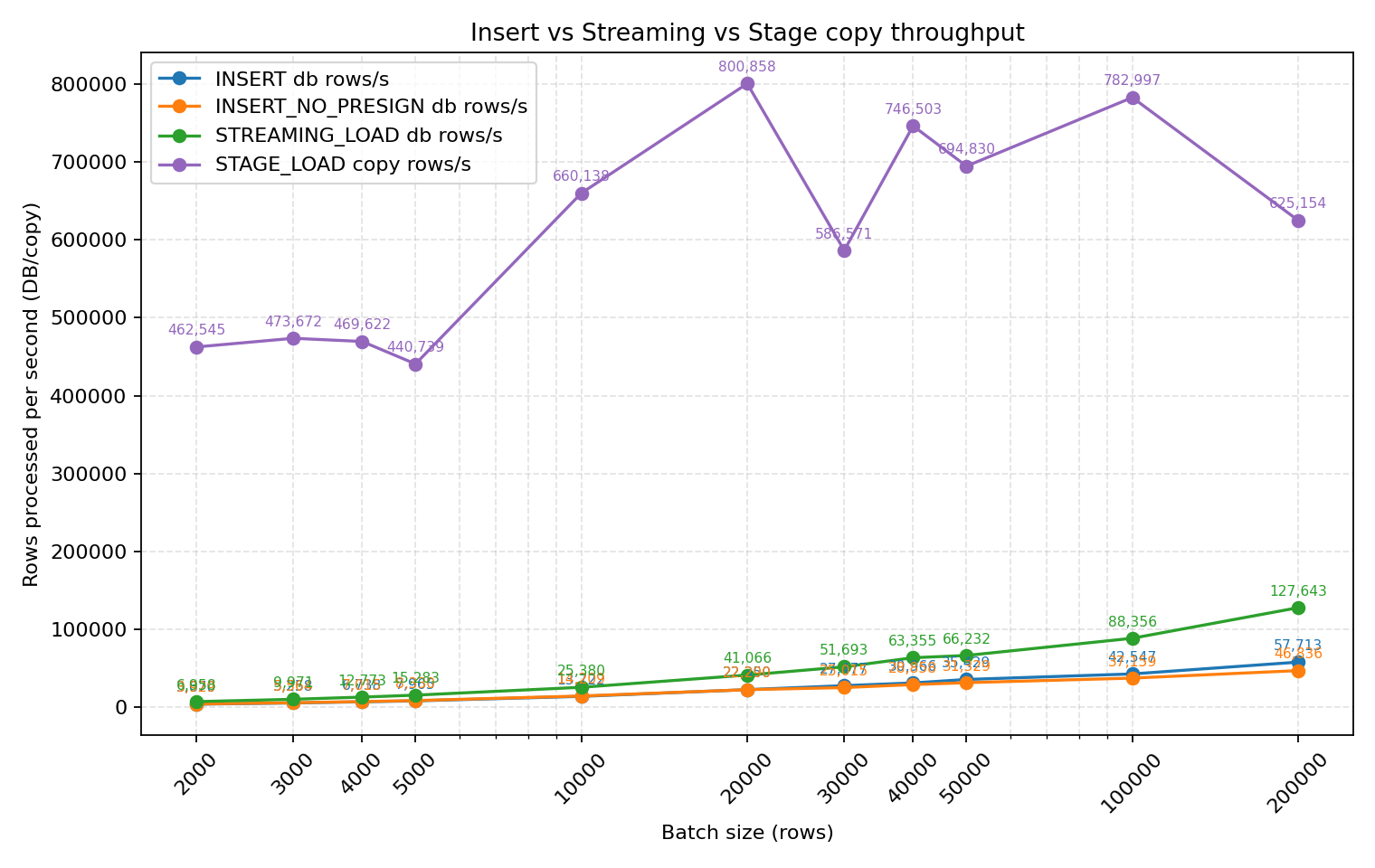
把四种方式放到一块对比,可以看出来 stage_load (copy into) 方式是遥遥领先于其它方式。实际生产环境 3 个节点的集群、数据源足够的情况下,COPY INTO 可以达到 230万+行/秒 的速度摄入。
copy into (stage_load) 这个方式的数据摄入,在数据源足够的情况下,每秒可以达到 100万行+ 也问题不大。 例如: 在 3 个节点的集群数据足够的情况下,每秒达到:230万+行/S 的速度摄入。 10000 rows read in 84.816 sec. Processed 200.19 million rows, 143.15 GiB (2.36 million rows/s, 1.69 GiB/s)
快速对比表
| 方式 | 吞吐性能 | 适用场景 | 云上成本 | 实现难度 |
|---|---|---|---|---|
| insert | ⭐⭐ | 云上 | 低 | 简单 |
| insert_no_presign | ⭐⭐ | 私有化 | - | 简单 |
| streaming_load | ⭐⭐⭐ | 私有化实时场景 | 高 | 中等 |
| stage_load (copy into) | ⭐⭐⭐⭐⭐ | 大批量加载 | 低 | 中等 |
几种方式选择的依据
看完上述数据,大家都会问:我该怎么选?是追求最高性能的 stage_load(copy into),还是图个方便?对于云上场景,还必须额外考虑“怎么能省钱”(面向金钱编程,是云上开发必修课)。
私有化 Databend 数据写入方式选择参考
在私有化环境下,我通常建议“怎么方便怎么来”,让开发者更快交付、业务更稳定是第一原则。从上面的图可以看到,各种方式的吞吐都能轻松达到秒级 3 万行以上,海量的数据每秒也可以轻松百万行的数据摄入,能满足业务就行。
- 没有其它原因,怎么简单怎么来,但是写入尽量 batch , 可以减少 Databend 的 compact 开销
- 对象存储无法对应用开放时,可选 streaming_load 或 insert_no_presign。两者中 insert_no_presign,只需在连接串中加 ,其它配置无需变。如果性能仍不满足,再考虑 streaming_load。presigned_url_disabled=true
- 单机网卡已经成为瓶颈时,可通过 stage_load 利用 OpenDAL 先把数据写入对象存储,再批量加载;可使用多台 Databend 并行加载,对象存储本身也能横向扩展,从而轻松实现秒级百万行加载。
公有云上 Databend 数据写入方式选择参考
线下以便利优先,而云上在能满足性能的前提下要尽量省钱。在这里建议排除 insert_no_presign 和 streaming_load,这两种方式可能触发跨 VPC 的流量费用,成本偏高。 在云上建议选择:
- Bulk insert
- stage_load (copy into )
这两种方都是先借助于对象存,用于先暂存数据,后面写入,利用对象存储从那里写都不收费的特性,来帮助用户降低云上的费用支出。 在云上更多情况下用户会借助于 Databend 的 task + copy into 实现数据的秒级加载。实现数据近实时摄入。
⚠️ 云上避坑指南:
不推荐使用: INSERT_NO_PRESIGN 和 STREAMING_LOAD
- 原因:这两种方式可能触发跨 VPC 的流量费用,成本偏高
Databend 在帮助云上用户实现湖仓建设或是改造时,发现很多客户在云上的数据入湖及读取相关的流量费用往往比较惊人,这些都是可以省下来的。如果你发现你们云上流量费也比较高的情况下,也可以联系 Databend 一起来分析一下。
最佳实践:
在云上,更多情况下用户会借助于 Databend 的 task + copy into 实现数据的秒级加载,从而实现数据近实时摄入。
-- 示例:创建定时任务,每分钟加载一次数据
CREATE TASK auto_ingest_task
WAREHOUSE = 'default'
SCHEDULE = 1 MINUTE
AS
COPY INTO target_table
FROM @my_stage
PATTERN = '.*\.csv'
FILE_FORMAT = (type = CSV)
PURGE = TRUE;
这个可以充分利用到云上对象存储的数据写入不收流量费,同时也可以利用 Databend 读取同 Region 的对象存储没有流量费的特性。
结论
通过这次压测可以看到,Databend 的不同写入方式在性能、成本与实现复杂度之间形成了清晰的梯度:streaming_load 在实时性与吞吐之间达到更好的平衡,而 stage_load 在吞吐层面有绝对优势,同时还能通过对象存储降低云端成本。因此在落地方案时,建议优先评估业务的实时性、网络拓扑和预算约束,再在 INSERT、STREAMING_LOAD 与 STAGE_LOAD 之间做取舍,同时通过合理的 batch 设置和自动化任务调度,既获得稳定的写入能力,也确保投入产出比最优。
从私有化到云上,数据写入的决策逻辑已经变了:不再是单纯 PK 性能,而是要在 性能与成本 之间找到最优平衡。选对方式,不仅能保证性能,还能大幅降低云上费用。看完上面的内容 Databend 支持 4 种写入方式你会如何选择呢?
如果本文对你有帮助,欢迎:
- ⭐ Star https://github.com/databendlabs/databend
- 💬 在 Issue 中分享你的使用场景和优化经验
- 📢 分享给更多需要的朋友
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


